Bemerkung
Hallo, willkommen in der SunFounder Raspberry Pi & Arduino & ESP32 Enthusiasten-Community auf Facebook! Tauchen Sie mit anderen Enthusiasten tiefer in Raspberry Pi, Arduino und ESP32 ein.
Warum beitreten?
Expertenunterstützung: Lösen Sie Probleme nach dem Kauf und technische Herausforderungen mit Hilfe unserer Community und unseres Teams.
Lernen & Teilen: Tauschen Sie Tipps und Tutorials aus, um Ihre Fähigkeiten zu verbessern.
Exklusive Vorschauen: Erhalten Sie frühzeitigen Zugang zu neuen Produktankündigungen und Sneak Peeks.
Sonderrabatte: Genießen Sie exklusive Rabatte auf unsere neuesten Produkte.
Festliche Aktionen und Gewinnspiele: Nehmen Sie an Gewinnspielen und Feiertagsaktionen teil.
👉 Bereit, mit uns zu entdecken und zu gestalten? Klicken Sie auf [here] und treten Sie noch heute bei!
(Beispiel) Buchexperte
Einführung
In diesem Projekt erstellen Sie einen AI-gestützten Buchcover-Analysator, der mithilfe von Computer Vision und natürlicher Sprachverarbeitung Bücher anhand ihrer Cover erkennt. Das System erfasst Bilder von Buchcovern mit einer Raspberry-Pi-Kamera, sendet sie zur Analyse an ein LLM-Modell (hier verwenden wir das Vision-Modell GPT-4o von OpenAI) und gibt anschließend per Text-to-Speech Informationen über den Buchtitel, den Autor, eine Zusammenfassung und die Rezeption des Buches aus.
Das Projekt kombiniert mehrere Technologien:
Bilderfassung mit Picamera2
Bildanalyse mit den Vision-Funktionen von GPT-4o
Text-to-Speech-Umwandlung für die Audioausgabe
RGB-LED für visuelles Status-Feedback
Physische Taste für eine intuitive Bedienung
Wenn Sie andere LLM-Modelle verwenden möchten, lesen Sie bitte 5. Verbindung mit Online-LLMs .
Was Sie benötigen
Für dieses Projekt werden die folgenden Komponenten benötigt:
COMPONENT |
PURCHASE LINK |
|---|---|
Raspberry Pi Camera Module |
|
- |
|
Book (for testing) |
- |
Schaltplan
Für eine komfortable Verwendung des Kameramoduls wird Pan-Tilt montieren (für die Kamera) empfohlen.
Bemerkung
Durch die Montage des Pan-Tilt-Moduls können einige Pins verdeckt werden. Daher wird empfohlen, es nur bei Verwendung der Kamera zu montieren oder es nach der Montage außen anzubringen.

Verbinden Sie die Komponenten wie folgt mit dem Fusion HAT+:
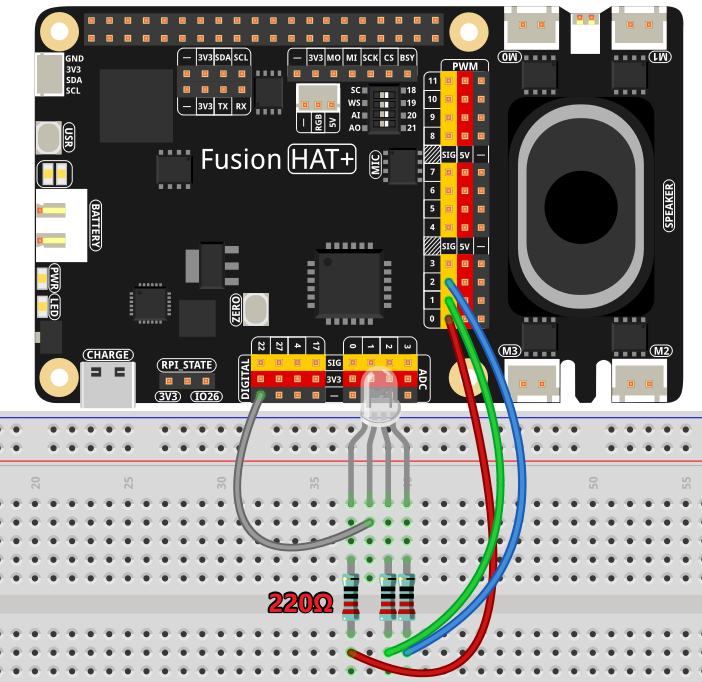
Die User-Taste ist bereits in das Fusion HAT+ integriert und benötigt keine zusätzliche Verkabelung. Sie befindet sich in der Nähe des BATTERY-Ports.*

API-Schlüssel erstellen und speichern
Gehen Sie zu OpenAI Platform und melden Sie sich an. Klicken Sie auf der Seite API keys auf Create new secret key.
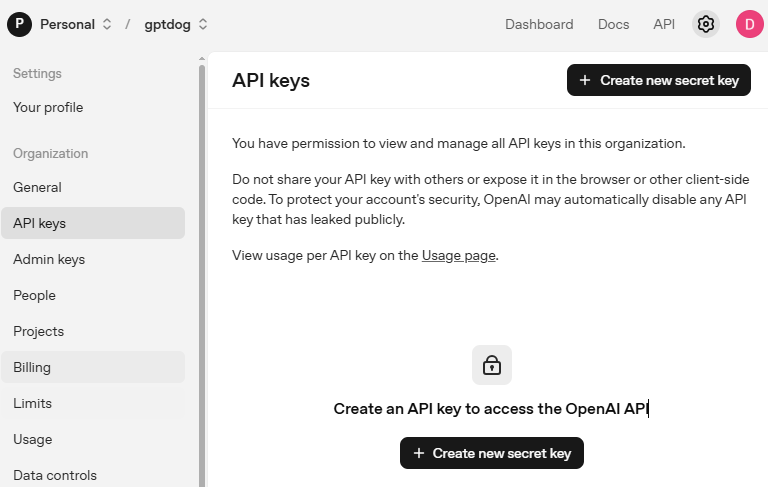
Füllen Sie die Angaben aus (Owner, Name, Project und gegebenenfalls Berechtigungen) und klicken Sie dann auf Create secret key.
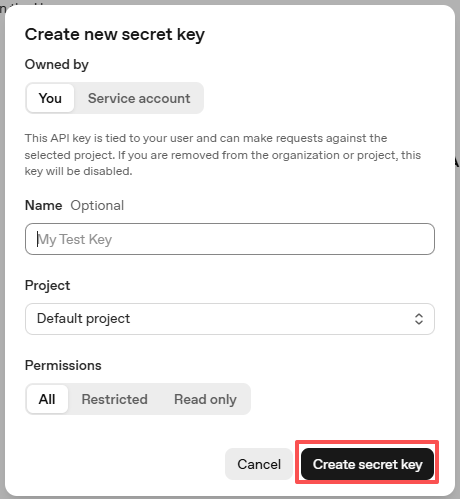
Sobald der Schlüssel erstellt wurde, kopieren Sie ihn sofort — später wird er nicht noch einmal angezeigt. Falls Sie ihn verlieren, müssen Sie einen neuen erstellen.
Erstellen Sie in Ihrem Projektordner (zum Beispiel:
/) eine Datei mit dem Namensecret.py:cd ~/ai-lab-kit/llm sudo nano secret.py
Fügen Sie Ihren Schlüssel wie folgt in die Datei ein:
# secret.py # Store secrets here. Never commit this file to Git. OPENAI_API_KEY = "sk-xxx"
Abrechnung aktivieren und Modelle prüfen
Bevor Sie den Schlüssel verwenden, öffnen Sie in Ihrem OpenAI-Konto die Seite Billing, hinterlegen Sie Ihre Zahlungsdaten und laden Sie ein kleines Guthaben auf.
Wechseln Sie anschließend zur Seite Limits, um zu prüfen, welche Modelle für Ihr Konto verfügbar sind, und kopieren Sie die genaue Modell-ID für die Verwendung im Code.
Beispiel ausführen
Greifen Sie auf den Raspberry-Pi-Desktop zu:
Remote Desktop: Verwenden Sie VNC für ein vollständiges Desktop-Erlebnis.
Raspberry Pi Connect: Verwenden Sie Raspberry Pi Connect, um sicher von jedem Browser aus auf Ihren Pi zuzugreifen.
Öffnen Sie ein Terminal und wechseln Sie in den Code-Ordner:
cd ~/ai-lab-kit/llm sudo python3 llm_openai_bookexpert.py
Wenn das Skript ausgeführt wird:
Ein Kamera-Vorschaufenster wird geöffnet
Die RGB-LED leuchtet blau und signalisiert den Bereitschaftszustand
Platzieren Sie ein Buchcover vor der Kamera
Drücken Sie die USR-Taste auf dem Fusion HAT+ (in der Nähe des BATTERY-Ports)
Das System wird dann:
Ein Foto aufnehmen (LED wird gelb 🟡)
Das Bild mit AI analysieren (LED wird violett 🟣)
Die Analyse aussprechen (LED wird grün 🟢)
In den Bereitschaftszustand zurückkehren (LED wird blau 🔵)
Bei einem Fehler wird die LED rot 🔴
Fotos werden unter ~/Pictures/book_covers/ gespeichert
Drücken Sie Ctrl+C, um das Programm zu beenden
Code
Hier ist das vollständige Python-Skript für den AI-Buchcover-Analysator:
#!/usr/bin/env python3
import os
import time
import re
import base64
import threading
from pathlib import Path
from picamera2 import Picamera2, Preview
from fusion_hat.user_button import UserButton
from fusion_hat.modules import RGB_LED
from fusion_hat.pwm import PWM
from fusion_hat.llm import OpenAI
from fusion_hat.tts import OpenAI_TTS
from secret import OPENAI_API_KEY
class BookCoverAnalyzer:
def __init__(self):
# Initialize LED for status feedback
self.rgb_led = RGB_LED(PWM(0), PWM(1), PWM(2), common=RGB_LED.CATHODE)
self.set_led_color("blue") # Ready state
# Initialize OpenAI LLM for image analysis
self.llm = OpenAI(
api_key=OPENAI_API_KEY,
model="gpt-4o", # GPT-4o supports image input
)
# Initialize TTS for audio responses
self.tts = OpenAI_TTS(api_key=OPENAI_API_KEY)
self.tts.set_voice(self.tts.Voice.ALLOY)
# Initialize camera
self.camera = Picamera2()
self.camera.configure(self.camera.create_preview_configuration(main={"size": (800, 600)}))
# Initialize button
self.btn = UserButton()
# Set up directories
self.real_user = os.getenv("SUDO_USER") or os.getlogin()
self.user_home = f"/home/{self.real_user}"
self.pictures_dir = Path(self.user_home) / "Pictures" / "book_covers"
self.pictures_dir.mkdir(parents=True, exist_ok=True)
# Threading locks
self.photo_lock = threading.Lock()
self.photo_index = 1
# Set LLM instructions
self.instructions = """You are a book expert. Analyze book covers that are sent to you.
When you receive a book cover image, provide:
1. Book title (if identifiable from cover)
2. Author (if identifiable from cover)
3. Brief summary of what the book is about (50 words)
4. Overall rating/reception (e.g., "Highly acclaimed", "Classic", "Popular", etc.)
Keep your response under 100 words total.
Speak in a friendly, informative tone suitable for an audio response.
If the image is not a book cover or is unclear, politely say you can't identify it and ask for another photo."""
self.llm.set_max_messages(10)
self.llm.set_instructions(self.instructions)
def set_led_color(self, color_name):
"""Set RGB LED color for status feedback"""
color_map = {
"red": (255, 0, 0),
"green": (0, 255, 0),
"blue": (0, 0, 255),
"yellow": (255, 255, 0),
"purple": (255, 0, 255),
"white": (255, 255, 255),
"off": (0, 0, 0),
}
if color_name in color_map:
self.rgb_led.color(color_map[color_name])
def capture_photo(self):
"""Capture a photo and return the filepath"""
with self.photo_lock:
filepath = self.pictures_dir / f"book_cover_{self.photo_index:03d}.jpg"
print(f"\n📸 Capturing photo: {filepath}")
# LED feedback: yellow for capturing
self.set_led_color("yellow")
# Capture image
self.camera.capture_file(str(filepath))
# Increment counter for next photo
self.photo_index += 1
print("Photo captured successfully")
return str(filepath)
def analyze_book_cover(self, image_path):
"""Send book cover image to OpenAI for analysis"""
print("\n Analyzing book cover...")
# LED feedback: purple for processing
self.set_led_color("purple")
try:
# use fusion_hat.llm's prompt method to process the image
prompt_text = "Please analyze this book cover and tell me about the book. Provide: 1) Book title if identifiable, 2) Author if identifiable, 3) Brief summary, 4) Overall rating/reception. Keep under 100 words."
print("Sending to AI for analysis...")
# method1: non-streaming response
response = self.llm.prompt(prompt_text, image_path=image_path)
# if the response is a string, use it directly
if isinstance(response, str):
analysis = response
else:
# if response is not a string, try to convert it to a string
analysis = str(response)
print(f"\n Analysis:\n{analysis}")
# LED feedback: green for success
self.set_led_color("green")
return analysis
except Exception as e:
print(f"Error analyzing image: {e}")
print(f"Error type: {type(e)}")
# method2: streaming response
try:
print("Trying stream method...")
stream_response = self.llm.prompt(prompt_text, stream=True, image_path=image_path)
# receive the stream response
analysis_parts = []
for next_word in stream_response:
if next_word:
analysis_parts.append(next_word)
analysis = ''.join(analysis_parts)
print(f"\n Analysis (stream):\n{analysis}")
# LED feedback: green for success
self.set_led_color("green")
return analysis
except Exception as e2:
print(f"Stream method also failed: {e2}")
# LED feedback: red for error
self.set_led_color("red")
return "Sorry, I couldn't analyze the book cover. Please make sure the book cover is clearly visible and try again."
def speak_response(self, text):
"""Convert text to speech"""
print("\nSpeaking response...")
# Clean up text for TTS (remove markdown, etc.)
clean_text = re.sub(r'[*_\[\]()#]', '', text)
# Speak with friendly instructions
self.tts.say(clean_text, instructions="speak clearly and warmly")
print("Response spoken")
# Return to ready state
self.set_led_color("blue")
def button_handler(self):
"""Handle button press: capture photo, analyze, and speak"""
print("\n" + "="*50)
print("Processing request...")
# Step 1: Capture photo
try:
image_path = self.capture_photo()
except Exception as e:
print(f"Failed to capture photo: {e}")
self.set_led_color("red")
self.tts.say("Sorry, I couldn't take a photo. Please try again.")
self.set_led_color("blue")
return
# Step 2: Analyze with AI
analysis = self.analyze_book_cover(image_path)
# Step 3: Speak the analysis
self.speak_response(analysis)
print(f"Complete! Photo saved at: {image_path}")
print("="*50 + "\n")
def run(self):
"""Main program loop"""
# Set button callback
self.btn.set_on_click(self.button_handler)
# Start camera preview
print("Starting camera preview...")
self.camera.start_preview(Preview.QT)
self.camera.start()
# LED feedback: blue for ready
self.set_led_color("blue")
print("\n" + "="*50)
print("BOOK COVER ANALYZER")
print("="*50)
print("\nReady to analyze book covers!")
print("Press the USR button to capture and analyze a book cover")
print("I will speak the analysis aloud")
print("LED colors:")
print(" Blue: Ready")
print(" Yellow: Capturing photo")
print(" Purple: Analyzing with AI")
print(" Green: Analysis successful")
print(" Red: Error occurred")
print(f"Photos saved to: {self.pictures_dir}")
print("Press Ctrl+C to exit")
print("="*50 + "\n")
try:
# Keep program running
while True:
time.sleep(0.1)
except KeyboardInterrupt:
print("\nExiting...")
finally:
# Cleanup
self.camera.stop_preview()
self.camera.close()
self.set_led_color("off")
print("Cleanup complete")
if __name__ == "__main__":
analyzer = BookCoverAnalyzer()
analyzer.run()
Code verstehen
Kamera-Initialisierung
Die Picamera2-Bibliothek bietet eine moderne Schnittstelle zur Steuerung der Raspberry-Pi-Kamera und unterstützt sowohl Bildaufnahme als auch Vorschau.
self.camera = Picamera2() self.camera.configure(self.camera.create_preview_configuration(main={"size": (800, 600)})) # Vorschau und Kamera starten self.camera.start_preview(Preview.QT) self.camera.start()
Bildaufnahme mit Thread-Sicherheit
Die Methode
capture_photoverwendet Thread-Locks, um mehrere gleichzeitige Aufnahmen zu verhindern und eine korrekte Dateibenennung sicherzustellen.def capture_photo(self): with self.photo_lock: filepath = self.pictures_dir / f"book_cover_{self.photo_index:03d}.jpg" self.camera.capture_file(str(filepath)) self.photo_index += 1 return str(filepath)
Vision-AI-Analyse
Das System nutzt die Vision-Funktionen von GPT-4o, um Buchcover zu analysieren. Zwei Methoden (Streaming und Nicht-Streaming) sind zur besseren Stabilität implementiert.
def analyze_book_cover(self, image_path): prompt_text = "Please analyze this book cover..." # Methode 1: Antwort ohne Streaming response = self.llm.prompt(prompt_text, image_path=image_path) # Methode 2: Fallback mit Streaming stream_response = self.llm.prompt(prompt_text, stream=True, image_path=image_path)
Text-to-Speech-Konvertierung
Die TTS-API von OpenAI wandelt die AI-Analyse in natürlich klingende Sprache um, mit konfigurierbaren Stimmenoptionen.
self.tts = OpenAI_TTS(api_key=OPENAI_API_KEY) self.tts.set_voice(self.tts.Voice.ALLOY) def speak_response(self, text): clean_text = re.sub(r'[*_\[\]()#]', '', text) # Markdown entfernen self.tts.say(clean_text, instructions="speak clearly and warmly")
Status-Feedback-System
Die RGB-LED liefert während des gesamten Ablaufs visuelles Feedback durch Farbcodierung:
def set_led_color(self, color_name): color_map = { "red": (255, 0, 0), # Fehler "green": (0, 255, 0), # Erfolg "blue": (0, 0, 255), # Bereit "yellow": (255, 255, 0), # Aufnahme "purple": (255, 0, 255), # Verarbeitung } self.rgb_led.color(color_map[color_name])
Button-Ereignisbehandlung
Die User-Taste startet den gesamten Analyseablauf über einen Ereignis-Callback.
def button_handler(self): # 1. Foto aufnehmen image_path = self.capture_photo() # 2. Mit AI analysieren analysis = self.analyze_book_cover(image_path) # 3. Analyse aussprechen self.speak_response(analysis) # Callback setzen self.btn.set_on_click(self.button_handler)
Dateiverwaltung
Fotos werden automatisch in datumsbasierten Ordnern mit fortlaufender Nummerierung gespeichert.
self.real_user = os.getenv("SUDO_USER") or os.getlogin() self.user_home = f"/home/{self.real_user}" self.pictures_dir = Path(self.user_home) / "Pictures" / "book_covers" self.pictures_dir.mkdir(parents=True, exist_ok=True)
Fehlerbehebung
Fehler „Camera not detected“
Stellen Sie sicher, dass das Kameraflachbandkabel korrekt eingesetzt ist (goldene Kontakte in die richtige Richtung)
Führen Sie
sudo raspi-configaus und aktivieren Sie das Kamera-InterfaceStarten Sie das System nach der Aktivierung neu
Kein Vorschaufenster erscheint
Stellen Sie sicher, dass Sie auf einem Raspberry Pi mit Desktop-Umgebung arbeiten
Für Headless-Betrieb entfernen oder ändern Sie den Vorschau-Code
Prüfen Sie, ob genügend GPU-Speicher zugewiesen ist
OpenAI-API-Fehler
Prüfen Sie, ob Ihr API-Schlüssel in
secret.pykorrekt ist und ausreichend Guthaben vorhanden istTesten Sie die Internetverbindung:
ping 8.8.8.8Stellen Sie sicher, dass Ihr Konto Zugriff auf GPT-4o und die TTS-API hat
TTS-Audio wird nicht abgespielt
Prüfen Sie die Audioausgabe:
sudo raspi-config→ System Options → AudioTesten Sie den Lautsprecher mit:
speaker-test -t sine -f 440Stellen Sie sicher, dass Lautsprecher oder Kopfhörer am richtigen Audioanschluss angeschlossen sind
Tastendruck wird nicht erkannt
Prüfen Sie, ob die LED der User-Taste beim Drücken aufleuchtet
Stellen Sie sicher, dass das Fusion HAT+ korrekt auf den GPIO-Pins sitzt
Überprüfen Sie, ob der Button-Callback korrekt gesetzt wurde
Bildanalyse liefert nur allgemeine Antworten
Sorgen Sie für gute Beleuchtung beim Fotografieren der Buchcover
Positionieren Sie das Buchcover möglichst gerade im Kamerabild
Testen Sie zunächst bekannte Bücher für bessere Erkennung
Reinigen Sie die Kameralinse, falls das Bild unscharf ist
Dieses Projekt demonstriert die leistungsstarke Kombination aus Computer Vision, natürlicher Sprachverarbeitung und physischem Computing, um ein intelligentes Buchanalyse-System zu erstellen. Es zeigt, wie AI alltägliche Interaktionen mit realen Objekten wie Büchern erweitern kann und Informationen zugänglicher sowie interaktiver macht.