2. 使用 Piper 和 OpenAI 进行文本转语音(TTS)
在上一节中,我们介绍了 Raspberry Pi 上的两种简单离线 TTS 引擎:Espeak 和 Pico2Wave。 现在,我们将进一步体验两种 更高级的 TTS 方案,它们具有 更高的语音质量 和更强的灵活性:
Piper —— 基于神经网络的高速 TTS 引擎,可在 Raspberry Pi 上 完全离线运行。
OpenAI TTS —— 在线语音服务,提供 非常自然、接近真人的语音效果,非常适合表达丰富的语音内容。
这些引擎可以让您的 Pironman 5 Pro MAX 发出的声音更加真实、生动。 🚀
1. 测试 Piper
Piper 是一个 离线神经网络 TTS 引擎,也就是说在模型安装完成后无需互联网连接即可使用。 它支持多种 语言 和 语音模型,因此非常适合嵌入式语音应用。
运行程序
cd ~/sunfounder-voice-assistant/examples sudo python3 tts_piper.py
第一次运行时,会自动下载所选择的 语音模型。
随后您将听到 Pironman 5 Pro MAX 说:
Hello! I'm Piper TTS.您可以通过调用
set_model()并指定不同的模型名称来切换语音或语言。
代码
from sunfounder_voice_assistant.tts import Piper
tts = Piper()
# List supported languages
print(tts.available_countrys())
# List models for English (en_us)
print(tts.available_models('en_us'))
# Set a voice model (auto-download if not already present)
tts.set_model("en_US-amy-low")
# Say something
tts.say("Hello! I'm Piper TTS.")
代码说明:
available_countrys()— 列出所有支持的语言。available_models()— 列出指定语言可用的语音模型。set_model()— 设置语音模型。如果该模型尚未安装,会自动下载。say()— 将文本转换为语音并立即播放。
💡 提示: 尝试不同的语音模型来比较速度、清晰度和口音。有些模型体积更小(速度更快),而有些模型则具有更高的语音质量。
2. 测试 OpenAI TTS
获取并保存 API Key
访问 OpenAI 平台 并登录。在 API keys 页面点击 Create new secret key。
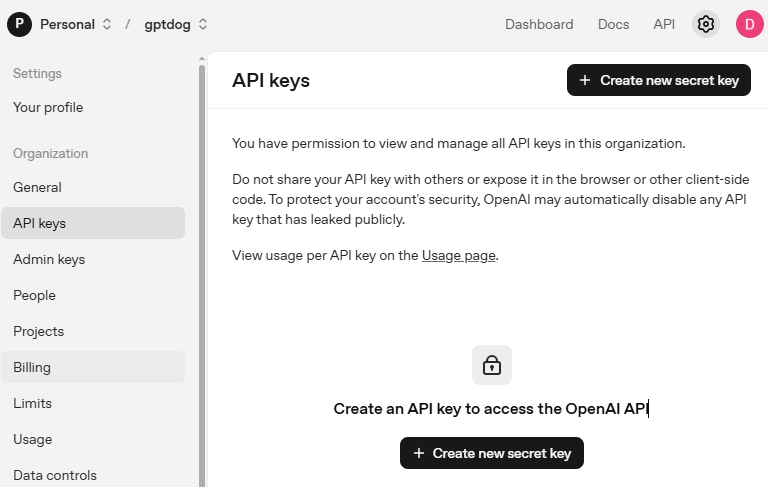
填写相关信息(Owner、Name、Project,以及必要时设置权限),然后点击 Create secret key。
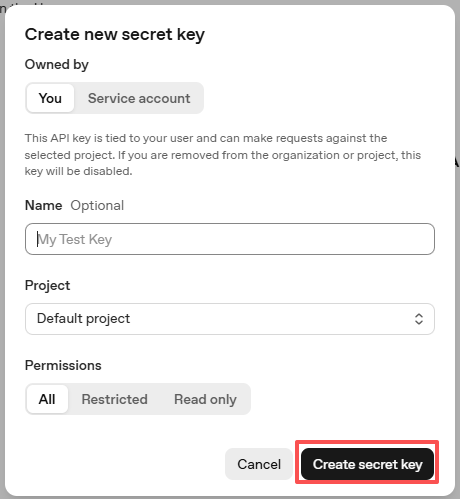
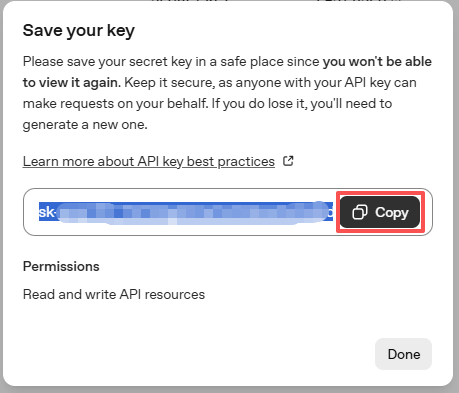
创建完成后,请立即复制该 key —— 之后将无法再次查看。如果丢失,则需要重新生成新的 key。
在您的项目目录中(例如:
~/sunfounder-voice-assistant/examples)创建一个名为secret.py的文件:cd ~/sunfounder-voice-assistant/examples sudo nano secret.py
将您的 key 写入文件,例如:
# secret.py # Store secrets here. Never commit this file to Git. OPENAI_API_KEY = "sk-xxx"
运行程序
cd ~/sunfounder-voice-assistant/examples
sudo python3 tts_openai.py
程序将连接到 OpenAI 的 TTS 服务,Pironman 5 Pro MAX 会使用 自然、富有表现力的语音 进行播报。
您可以更改 语音风格,并通过添加 instructions 来控制语气和情绪(例如:悲伤、戏剧化或活泼)。
这使得 OpenAI TTS 非常适用于交互式机器人、讲故事应用或教育助手。
代码
from sunfounder_voice_assistant.tts import OpenAI_TTS
from secret import OPENAI_API_KEY
# Export your OpenAI_API_KEY before running the script
# export OPENAI_API_KEY="sk-proj-xxxxxx"
tts = OpenAI_TTS(api_key=OPENAI_API_KEY)
# tts.set_model('tts-1')
tts.set_voice('alloy')
tts.set_model('gpt-4o-mini-tts')
msg = "Hello! I'm OpenAI TTS."
print(f"Say: {msg}")
tts.say(msg)
msg = "with instructions, I can say word sadly"
instructions = "say it sadly"
print(f"Say: {msg}, with instructions: '{instructions}'")
tts.say(msg, instructions=instructions)
msg = "or say something dramaticly."
instructions = "say it dramaticly"
print(f"Say: {msg}, with instructions: '{instructions}'")
tts.say(msg, instructions=instructions)
代码说明:
OpenAI_TTS()— 使用您的 API key 初始化 OpenAI TTS 引擎。set_model()— 选择 TTS 模型(例如gpt-4o-mini-tts)。set_voice()— 选择具体的语音(例如alloy)。say(text)— 将文本转换为语音并播放。say(text, instructions=...)— 添加 语气控制指令,可动态调整语音表达风格。
示例:
“say it sadly” → 语气柔和、带有情绪
“say it dramatically” → 表达更夸张、富有戏剧感
“say it excitedly” → 语气兴奋、充满活力
故障排查
No module named ‘secret’
这表示
secret.py不在当前 Python 文件所在目录。 请将secret.py放到运行脚本的同一目录,例如:ls ~/ # 确认能看到:secret.py 和你的 .py 文件
OpenAI: Invalid API key / 401
检查您粘贴的 key 是否完整(通常以
sk-开头),并确认没有多余空格或换行。确认代码中正确导入:
from secret import OPENAI_API_KEY
确认 Raspberry Pi 可以访问网络(可尝试
ping api.openai.com)。
OpenAI: Quota exceeded / billing error
您可能需要在 OpenAI 控制台中添加计费方式或提高配额。
解决账户或计费问题后重新运行。
Piper:执行 ``tts.say()`` 但没有声音
确认语音模型确实存在:
ls ~/.local/share/piper/voices确认代码中的模型名称完全一致:
tts.set_model("en_US-amy-low")
检查 Raspberry Pi 的音频输出设备和音量(
alsamixer),并确认扬声器已连接且已供电。
ALSA / 声音设备错误(例如 “Audio device busy” 或 “No such file or directory”)
关闭其他正在使用音频设备的程序。
如果设备一直处于占用状态,尝试重启 Raspberry Pi。
如果使用 HDMI 或耳机接口输出,请在 Raspberry Pi OS 的音频设置中选择正确的设备。
运行 Python 时出现 Permission denied
如果环境需要权限,可尝试使用
sudo:sudo python3 tts_piper.py
TTS 引擎对比
项目 |
Espeak |
Pico2Wave |
Piper |
OpenAI TTS |
|---|---|---|---|---|
运行环境 |
Raspberry Pi 内置(离线) |
Raspberry Pi 内置(离线) |
Raspberry Pi / PC(离线,需要模型) |
云端(在线,需要 API key) |
语音质量 |
机械化 |
比 Espeak 更自然 |
自然(神经网络 TTS) |
非常自然、接近真人 |
可控制项 |
语速、音调、音量 |
控制项较少 |
可选择不同语音/模型 |
可选择模型和语音 |
语言支持 |
多种语言(质量不一) |
支持语言较少 |
多种语音和语言 |
英语效果最佳(其他语言视模型而定) |
延迟 / 速度 |
非常快 |
快 |
在 Pi 4/5 上使用 “low” 模型可实时运行 |
依赖网络(通常延迟较低) |
配置难度 |
非常简单 |
非常简单 |
需要下载 |
需要创建 API key 并安装客户端 |
适用场景 |
快速测试、简单提示 |
稍好一点的离线语音 |
本地项目中需要更好语音质量 |
最高质量、丰富语音效果 |