4. 使用 Ollama 实现文本 + 视觉对话
在本课程中,您将学习如何使用 Ollama —— 一个用于在本地运行大语言模型和视觉模型的工具。 我们将演示如何安装 Ollama、下载模型,并将 Pironman 5 Pro MAX 连接到该服务。
完成设置后,Pironman 5 Pro MAX 可以通过摄像头拍摄图像,然后由模型进行 视觉理解与描述 —— 您可以针对图像提出任何问题,模型将以自然语言进行回答。
1. 安装 Ollama(LLM)并下载模型
您可以选择将 Ollama 安装在以下位置:
Raspberry Pi 上(本地运行)
或同一局域网中的另一台计算机(Mac / Windows / Linux)
模型大小与硬件建议
您可以从 Ollama Hub 选择任意可用模型。 模型有不同规模(3B、7B、13B、70B 等)。 较小的模型运行速度更快、内存需求更低,而较大的模型质量更高,但需要更强的硬件支持。
请参考下表选择适合您设备的模型规模。
模型规模 |
最低内存要求 |
推荐硬件 |
|---|---|---|
~3B 参数 |
8GB(建议 16GB) |
Raspberry Pi 5(16GB)或中端 PC / Mac |
~7B 参数 |
16GB+ |
Pi 5(16GB,可运行但性能有限)或中端 PC / Mac |
~13B 参数 |
32GB+ |
高内存台式 PC / Mac |
30B+ 参数 |
64GB+ |
工作站 / 服务器 / 建议使用 GPU |
70B+ 参数 |
128GB+ |
多 GPU 高端服务器 |
在 Raspberry Pi 上安装
如果您希望在 Raspberry Pi 上直接运行 Ollama:
使用 64 位 Raspberry Pi OS
强烈建议使用 Raspberry Pi 5(16GB RAM)
运行以下命令:
# 安装 Ollama
curl -fsSL https://ollama.com/install.sh | sh
# 下载一个轻量级模型(适合测试)
ollama pull llama3.2:3b
# 快速运行测试(输入 'hi' 并按回车)
ollama run llama3.2:3b
# 启动 API 服务(默认端口 11434)
# 提示:设置 OLLAMA_HOST=0.0.0.0 以允许局域网访问
OLLAMA_HOST=0.0.0.0 ollama serve
在 Mac / Windows / Linux 上安装(桌面应用)
从 Ollama 下载页面 下载并安装 Ollama
打开 Ollama 应用,进入 Model Selector,在搜索栏中查找模型。例如输入
llama3.2:3b(一个适合入门的轻量级模型)。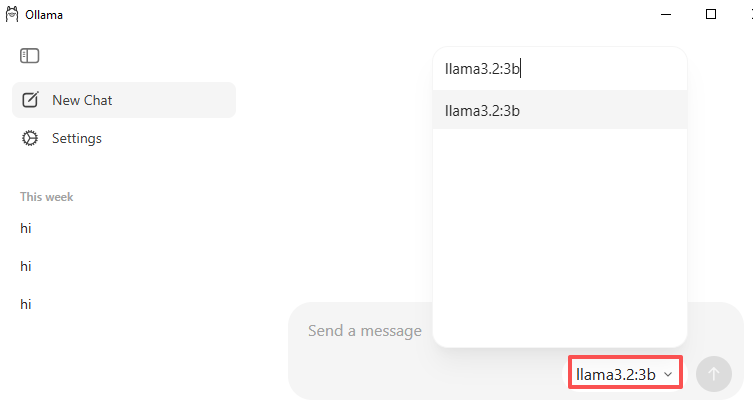
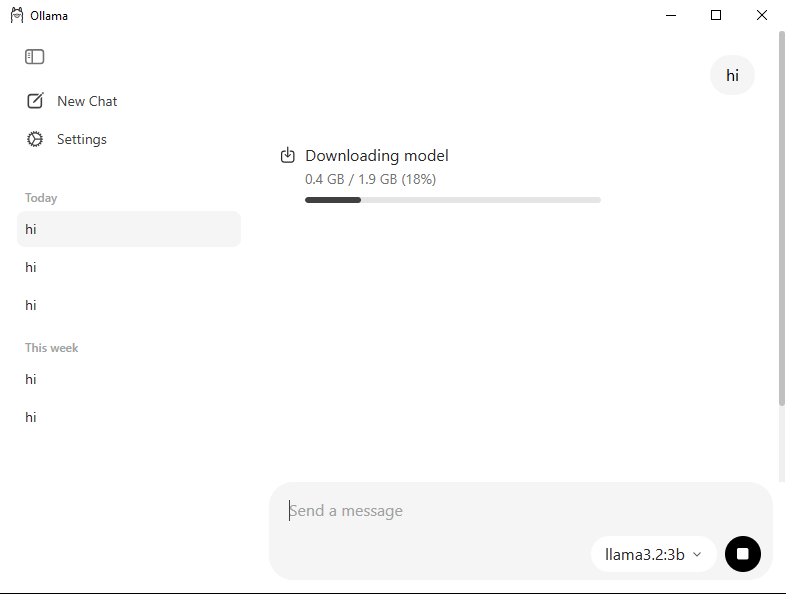
下载完成后,在聊天窗口输入简单内容(例如 “Hi”)。当您首次使用模型时,Ollama 会自动开始下载。
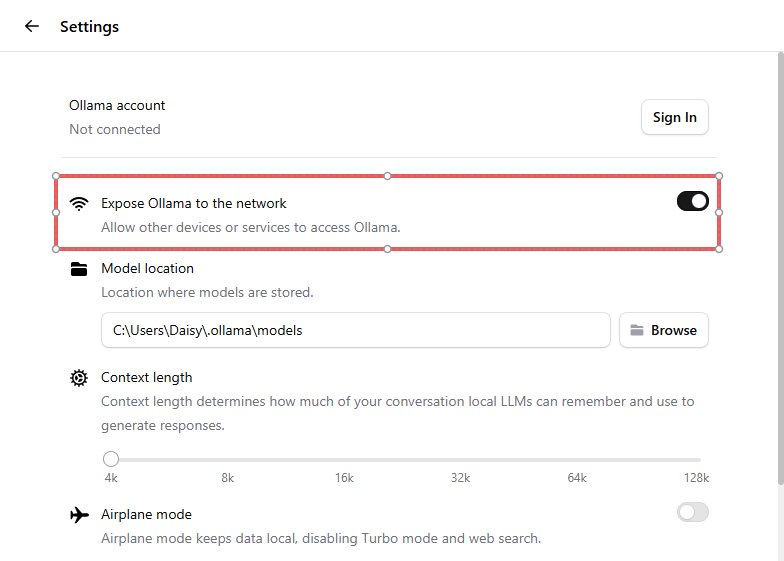
进入 Settings → 启用 Expose Ollama to the network。这样 Raspberry Pi 就可以通过局域网连接到该服务。
警告
如果出现如下错误:
Error: model requires more system memory ...
说明模型规模超过了设备的内存容量。 请使用 更小的模型,或切换到拥有更大 RAM 的计算机。
2. 测试 Ollama
当 Ollama 安装完成并且模型准备就绪后,您可以通过一个简单的聊天程序快速测试。
运行程序
cd ~/sunfounder-voice-assistant/examples sudo python3 llm_ollama.py
现在您可以在终端中直接与 Pironman 5 Pro MAX 进行对话。
您可以选择 Ollama Hub 中的 任意模型,但如果设备只有 8–16GB RAM,建议使用较小的模型(例如
moondream:1.8b、phi3:mini)。确保代码中指定的模型名称与您在 Ollama 中已下载的模型一致。
输入
exit或quit可退出程序。如果无法连接,请确认 Ollama 正在运行;若使用远程主机,请确保两台设备位于同一局域网。
代码
from sunfounder_voice_assistant.llm import Ollama
INSTRUCTIONS = "You are a helpful assistant."
WELCOME = "Hello, I am a helpful assistant. How can I help you?"
# Change this to your computer IP, if you run it on your pi, then change it to localhost
llm = Ollama(
ip="localhost",
model="llama3.2:3b"
)
# Set how many messages to keep
llm.set_max_messages(20)
# Set instructions
llm.set_instructions(INSTRUCTIONS)
# Set welcome message
llm.set_welcome(WELCOME)
print(WELCOME)
while True:
input_text = input(">>> ")
# Response without stream
# response = llm.prompt(input_text)
# print(f"response: {response}")
# Response with stream
response = llm.prompt(input_text, stream=True)
for next_word in response:
if next_word:
print(next_word, end="", flush=True)
print("")
3. 使用 Ollama 进行视觉对话
在此示例中,每当您输入一个问题时,Pi 摄像头都会 拍摄一张新的照片。 程序会通过 Ollama 将 您输入的文本 + 新拍摄的照片 发送给本地视觉模型, 然后以普通英文 实时输出模型的回复。
这是一个最基础的 “see & tell(看图描述)” 示例,您可以在此基础上进一步扩展,例如添加颜色识别、人脸检测或 QR 码识别等功能。
开始之前
打开 Ollama 应用(或运行 Ollama 服务),并确保已下载 支持视觉的模型。
如果您的设备拥有足够内存(≥16GB RAM),可以尝试
llava:7b。如果只有 8GB RAM,建议使用更小的模型,例如
moondream:1.8b或granite3.2-vision:2b。
运行示例
进入示例目录并运行脚本:
cd ~/sunfounder-voice-assistant/examples python3 llm_ollama_with_image.py
程序运行后的流程:
程序会打印欢迎信息,并等待您的输入(
>>>)。每当您输入任何内容 (例如 “hello”、“Is there yellow?”、“Any faces?”、“What is on the desk?”)时,程序将会:
从 Pi 摄像头拍摄一张照片 (保存到
/tmp/llm-img.jpg),将您的文本 + 该照片 发送给 Ollama 中的视觉模型,
实时输出 模型生成的回答到终端。
输入
exit或quit即可结束程序。
代码
from sunfounder_voice_assistant.llm import Ollama
from picamera2 import Picamera2
import time
'''
You need to setup ollama first, see llm_local.py
You need at leaset 8GB RAM to run llava:7b large multimodal model
'''
INSTRUCTIONS = "You are a helpful assistant."
WELCOME = "Hello, I am a helpful assistant. How can I help you?"
llm = Ollama(
ip="localhost", # e.g., "192.168.100.145" if remote
model="llava:7b" # change to "moondream:1.8b" or "granite3.2-vision:2b" for 8GB RAM
)
# Set how many messages to keep
llm.set_max_messages(20)
# Set instructions
llm.set_instructions(INSTRUCTIONS)
# Set welcome message
llm.set_welcome(WELCOME)
# Init camera
camera = Picamera2()
config = camera.create_still_configuration(
main={"size": (1280, 720)},
)
camera.configure(config)
camera.start()
time.sleep(2)
print(WELCOME)
while True:
input_text = input(">>> ")
# Capture image
img_path = '/tmp/llm-img.jpg'
camera.capture_file(img_path)
# Response without stream
# response = llm.prompt(input_text, image_path=img_path)
# print(f"response: {response}")
# Response with stream
response = llm.prompt(input_text, stream=True, image_path=img_path)
for next_word in response:
if next_word:
print(next_word, end="", flush=True)
print("")
故障排查
我遇到了类似这样的错误:`model requires more system memory …`。
这表示当前模型对设备内存的要求超出了您的设备能力。
请改用更小的模型,例如
moondream:1.8b或granite3.2-vision:2b。或者切换到拥有更大 RAM 的设备,并将 Ollama 暴露到局域网中供 Raspberry Pi 访问。
代码无法连接到 Ollama(connection refused)。
请检查以下内容:
确保 Ollama 正在运行(
ollama serve或桌面应用已打开)。如果使用的是另一台远程计算机,请在 Ollama 设置中启用 Expose to network。
再次确认代码中的
ip="..."是否填写为正确的局域网 IP 地址。确保两台设备位于同一局域网内。
我的 Pi 摄像头无法拍摄图像。
请确认
Picamera2已正确安装,并可通过简单测试脚本正常工作。检查摄像头排线是否连接正确,并确认已在
raspi-config中启用摄像头。确保脚本有权限写入目标路径(
/tmp/llm-img.jpg)。
输出速度太慢。
较小的模型响应速度更快,但回答内容通常也会相对简单。
您可以降低摄像头分辨率(例如使用 640×480 而不是 1280×720)以加快图像处理速度。
关闭 Raspberry Pi 上的其他程序,以释放更多 CPU 和 RAM 资源。