Nota
Hola, bienvenido a la Comunidad de Entusiastas de Raspberry Pi, Arduino y ESP32 de SunFounder en Facebook. Profundice en Raspberry Pi, Arduino y ESP32 junto a otros entusiastas.
¿Por qué unirte?
Soporte de Expertos: Resuelve problemas post-venta y desafíos técnicos con la ayuda de nuestra comunidad y equipo.
Aprende y Comparte: Intercambia consejos y tutoriales para mejorar tus habilidades.
Vistas Previas Exclusivas: Obtén acceso anticipado a nuevos anuncios de productos y vistas previas.
Descuentos Especiales: Disfruta de descuentos exclusivos en nuestros productos más nuevos.
Promociones y Sorteos Festivos: Participa en sorteos y promociones de temporada.
👉 ¿Listo para explorar y crear con nosotros? Haz clic en [aquí] y únete hoy.
2. TTS con Piper y OpenAI
En la lección anterior, exploramos Espeak y Pico2Wave, dos motores TTS offline simples en Raspberry Pi. Ahora, demos un gran paso adelante y probemos dos opciones TTS más avanzadas que ofrecen mayor calidad de voz y más flexibilidad:
Piper — un motor TTS rápido basado en redes neuronales que se ejecuta completamente offline en Raspberry Pi.
OpenAI TTS — un servicio en línea que proporciona voces muy naturales y humanas, perfecto para un habla expresiva.
Estos motores harán que su Pironman 5 Pro MAX suene más realista y vivo. 🚀
1. Probando Piper
Piper es un motor TTS neural offline, lo que significa que no necesita conexión a internet una vez instalado el modelo. Soporta múltiples idiomas y voces, lo que lo convierte en una opción potente para voz en sistemas embebidos.
Ejecutar el programa
cd ~/sunfounder-voice-assistant/examples sudo python3 tts_piper.py
La primera vez que lo ejecute, el modelo de voz seleccionado se descargará automáticamente.
Luego debería escuchar al Pironman 5 Pro MAX decir:
Hello! I'm Piper TTS.Puede cambiar de voces o idiomas llamando a
set_model()con un nombre de modelo diferente.
Código
from sunfounder_voice_assistant.tts import Piper
tts = Piper()
# Listar idiomas soportados
print(tts.available_countrys())
# Listar modelos para inglés (en_us)
print(tts.available_models('en_us'))
# Establecer un modelo de voz (se descarga automáticamente si no está presente)
tts.set_model("en_US-amy-low")
# Decir algo
tts.say("Hello! I'm Piper TTS.")
Explicación del código:
available_countrys()— Lista todos los idiomas soportados.available_models()— Lista los modelos disponibles para un idioma específico.set_model()— Establece el modelo de voz. Si el modelo no está instalado, se descargará automáticamente.say()— Convierte texto a voz y lo reproduce inmediatamente.
💡 Consejo: Pruebe diferentes modelos para comparar velocidad, claridad y acentos. Algunos modelos son más ligeros (más rápidos), mientras que otros tienen mayor fidelidad.
2. Probando OpenAI TTS
Obtener y guardar su clave API
Vaya a OpenAI Platform e inicie sesión. En la página API keys, haga clic en Create new secret key.
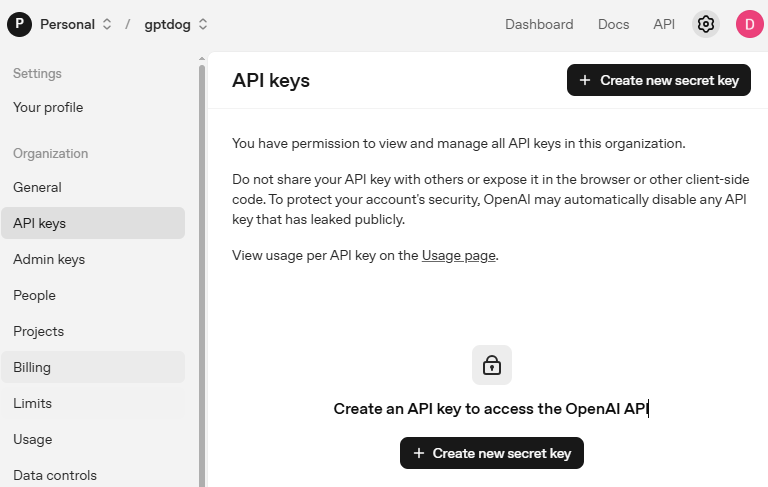
Complete los detalles (Owner, Name, Project y permisos si es necesario), luego haga clic en Create secret key.
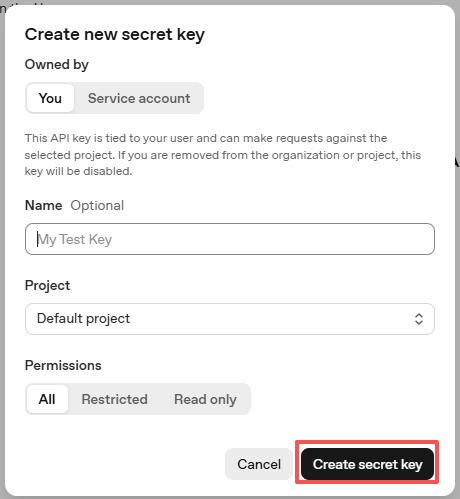
Una vez creada la clave, cópiela de inmediato — no podrá volver a verla. Si la pierde, deberá generar una nueva.
En la carpeta de su proyecto (por ejemplo:
/), cree un archivo llamadosecret.py:cd ~/sunfounder-voice-assistant/examples sudo nano secret.py
Pegue su clave en el archivo de esta manera:
# secret.py # Store secrets here. Never commit this file to Git. OPENAI_API_KEY = "sk-xxx"
Ejecutar el programa
cd ~/sunfounder-voice-assistant/examples
sudo python3 tts_openai.py
El programa se conectará al servicio TTS de OpenAI, y el Pironman 5 Pro MAX hablará usando una salida de voz natural y expresiva.
Puede cambiar estilos de voz y agregar instrucciones para controlar el tono y la expresión (por ejemplo, triste, dramático, juguetón).
Esto hace que OpenAI TTS sea ideal para robots interactivos, narración de cuentos o asistentes educativos.
Código
from sunfounder_voice_assistant.tts import OpenAI_TTS
from secret import OPENAI_API_KEY
# Exporte su OPENAI_API_KEY antes de ejecutar el script
# export OPENAI_API_KEY="sk-proj-xxxxxx"
tts = OpenAI_TTS(api_key=OPENAI_API_KEY)
# tts.set_model('tts-1')
tts.set_voice('alloy')
tts.set_model('gpt-4o-mini-tts')
msg = "Hello! I'm OpenAI TTS."
print(f"Say: {msg}")
tts.say(msg)
msg = "with instructions, I can say word sadly"
instructions = "say it sadly"
print(f"Say: {msg}, with instructions: '{instructions}'")
tts.say(msg, instructions=instructions)
msg = "or say something dramaticly."
instructions = "say it dramaticly"
print(f"Say: {msg}, with instructions: '{instructions}'")
tts.say(msg, instructions=instructions)
Explicación del código:
OpenAI_TTS()— Inicializa el motor TTS de OpenAI usando su clave API.set_model()— Selecciona el modelo TTS (por ejemplo,gpt-4o-mini-tts).set_voice()— Elige una voz específica (por ejemplo,alloy).say(text)— Convierte el texto a voz y lo reproduce.say(text, instructions=...)— Agrega instrucciones de tono expresivo, permitiéndole controlar dinámicamente el estilo del habla.
Ejemplo:
“say it sadly” → tono suave y emocional
“say it dramatically” → expresión audaz y enfática
“say it excitedly” → tono entusiasta
Solución de Problemas
No module named “secret”
Esto significa que
secret.pyno está en la misma carpeta que su archivo Python. Muevasecret.pyal mismo directorio donde ejecuta el script, por ejemplo:ls ~/ # Asegúrese de ver ambos: secret.py y su archivo .py
OpenAI: Invalid API key / 401
Verifique que pegó la clave completa (comienza con
sk-) y que no haya espacios o líneas nuevas adicionales.Asegúrese de que su código la importe correctamente:
from secret import OPENAI_API_KEY
Confirme el acceso a la red en su Pi (pruebe
ping api.openai.com).
OpenAI: Quota exceeded / billing error
Es posible que necesite agregar un método de facturación o aumentar la cuota en el panel de OpenAI.
Intente nuevamente después de resolver el problema de la cuenta/facturación.
Piper: tts.say() se ejecuta pero no hay sonido
Asegúrese de que un modelo de voz esté realmente presente:
ls ~/.local/share/piper/voicesConfirme que el nombre del modelo coincida exactamente en el código:
tts.set_model("en_US-amy-low")
Verifique el dispositivo/salida de audio y el volumen en su Pi (
alsamixer), y que los altavoces estén conectados y encendidos.
Errores de ALSA / dispositivo de sonido (ej., “Audio device busy” o “No such file or directory”)
Cierre otros programas que estén usando el audio.
Reinicie el Pi si el dispositivo permanece ocupado.
Para salida HDMI vs. jack de auriculares, seleccione el dispositivo correcto en la configuración de audio de Raspberry Pi OS.
Permiso denegado al ejecutar Python
Pruebe con
sudosi su entorno lo requiere:sudo python3 tts_piper.py
Comparación de Motores TTS
Característica |
Espeak |
Pico2Wave |
Piper |
OpenAI TTS |
|---|---|---|---|---|
Ejecución |
Integrado en Raspberry Pi (offline) |
Integrado en Raspberry Pi (offline) |
Raspberry Pi / PC (offline, necesita modelo) |
Nube (en línea, necesita clave API) |
Calidad de voz |
Robótica |
Más natural que Espeak |
Natural (TTS neural) |
Muy natural / humana |
Controles |
Velocidad, tono, volumen |
Controles limitados |
Elegir diferentes voces/modelos |
Elegir modelo y voces |
Idiomas |
Muchos (la calidad varía) |
Conjunto limitado |
Muchas voces/idiomas disponibles |
Mejor en inglés (otros varían según disponibilidad) |
Latencia / velocidad |
Muy rápida |
Rápida |
Tiempo real en Pi 4/5 con modelos “low” |
Dependiente de la red (generalmente baja latencia) |
Configuración |
Mínima |
Mínima |
Descargar modelos |
Crear clave API, instalar cliente |
Mejor para |
Pruebas rápidas, mensajes básicos |
Voz offline ligeramente mejor |
Proyectos locales con mejor calidad |
Máxima calidad, opciones de voz ricas |