Bemerkung
Hallo, willkommen in der SunFounder Raspberry Pi & Arduino & ESP32 Enthusiasten-Community auf Facebook! Tauchen Sie mit anderen Enthusiasten tiefer in Raspberry Pi, Arduino und ESP32 ein.
Warum beitreten?
Expertenunterstützung: Lösen Sie Probleme nach dem Kauf und technische Herausforderungen mit Hilfe unserer Community und unseres Teams.
Lernen & Teilen: Tauschen Sie Tipps und Tutorials aus, um Ihre Fähigkeiten zu verbessern.
Exklusive Vorschauen: Erhalten Sie frühzeitigen Zugang zu neuen Produktankündigungen und Sneak Peeks.
Sonderrabatte: Genießen Sie exklusive Rabatte auf unsere neuesten Produkte.
Festliche Aktionen und Gewinnspiele: Nehmen Sie an Gewinnspielen und Feiertagsaktionen teil.
👉 Bereit, mit uns zu entdecken und zu gestalten? Klicken Sie auf [here] und treten Sie noch heute bei!
6. Hand-Gestenerkenner
1. Überblick
Im vorherigen Kapitel haben wir MediaPipe Hands verwendet, um 21 Hand-Landmarks zu erfassen und das Hand-Skelett zu visualisieren.
Dieses Kapitel stellt MediaPipe Tasks – Gesture Recognizer vor, der semantische Gestenbezeichnungen direkt ausgeben kann, wie zum Beispiel:
Thumb_UpOpen_PalmVictoryClosed_Fist
Durch die Kombination von:
Picamera2für die VideoaufnahmeMediaPipe Handsfür die Landmark-VisualisierungGesture Recognizerfür die Klassifizierung
können wir eine Echtzeit-Gestenerkennung mit sowohl Skelettdarstellung als auch Label-Anzeige umsetzen.
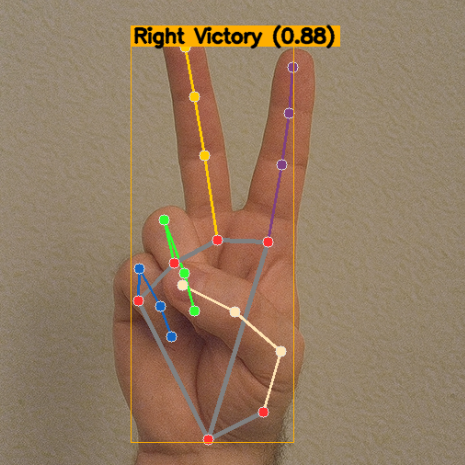
2. Funktionsweise
Das Programm führt die folgenden Schritte aus:
Erfassen von Videoframes mit
Picamera2.(Optional) Verwenden von
MediaPipe Handszum Zeichnen der Landmarks.Verwenden von MediaPipe Tasks – Gesture Recognizer im
VIDEO-Modus.Für jede erkannte Hand werden folgende Informationen ermittelt:
Gestenkategorienliste (Label + Konfidenz)
Händigkeit (Links / Rechts)
Normalisierte Landmarks
Auswahl der Top-1-Geste und Zeichnen von „Label + Konfidenzwert“ über der entsprechenden Hand.
Bemerkung
In diesem Kapitel wird die MediaPipe Tasks API (0.10+) verwendet.
3. Modell
Der Gesture Recognizer benötigt eine Modelldatei:
gesture_recognizer.task
Die Modelldatei ist bereits im Beispielverzeichnis enthalten. Bitte verwenden Sie die bereitgestellte Version.
Das integrierte Modell unterstützt die folgenden Gestenbezeichnungen:
0 →
Unknown1 →
Closed_Fist2 →
Open_Palm3 →
Pointing_Up4 →
Thumb_Down5 →
Thumb_Up6 →
Victory7 →
ILoveYou
4. Code ausführen
Wichtig
Stellen Sie vor dem Start sicher, dass:
das Pan-Tilt-Modul montiert ist
Sie Zugriff auf den Raspberry Pi Desktop haben
das Codepaket installiert ist
das Fusion HAT+ installiert und konfiguriert ist
OpenCV installiert ist
Detaillierte Anweisungen finden Sie unter 0. OpenCV einrichten.
Öffnen Sie das Terminal und geben Sie den folgenden Befehl ein:
sudo python3 ~/ai-lab-kit/mediapipe/mp_hand_gesture.py
Nach dem Start des Programms öffnet sich ein Fenster mit dem Titel „Show Video“ und zeigt den Live-Kamerastream an.
Wenn eine oder zwei Hände vor der Kamera erscheinen, führt das Programm Folgendes aus:
Es erkennt und zeichnet in Echtzeit die 21 Hand-Landmarks und Verbindungslinien (Hand-Skelett).
Es führt das Gesture-Recognizer-Modell für jedes Frame aus, um die Geste zu klassifizieren.
Wenn eine Geste mit einem Wert über
SCORE_THRESHOLD(Standardwert 0,5) erkannt wird, zeigt das Programm in der Nähe der entsprechenden Hand ein Label an, einschließlich:Händigkeit (Links/Rechts)
Gestenname (zum Beispiel
Thumb_Up,Open_Palm,Victory)Konfidenzwert (zum Beispiel
0.87)
Zusätzlich wird ein dünner Begrenzungsrahmen um den Handbereich gezeichnet, damit die Platzierung des Labels klarer wird.
Während Sie Ihre Handhaltung verändern, werden Gestenlabel und Wert kontinuierlich in Echtzeit aktualisiert.
Wenn keine Hand erkannt wird oder die Gestenkonfidenz unter dem Schwellenwert liegt, wird nur das Hand-Skelett (oder der rohe Kamerastream) ohne Gestenlabel angezeigt.
Drücken Sie
q, um das Programm zu beenden. Die Kamera stoppt und das OpenCV-Fenster wird automatisch geschlossen.
5. Vollständiger Code
from picamera2 import Picamera2, Preview
import cv2
import numpy as np
import mediapipe.python.solutions.hands as mp_hands
import mediapipe.python.solutions.drawing_utils as drawing
import mediapipe.python.solutions.drawing_styles as drawing_styles
# Import MediaPipe Tasks (Gesture Recognizer)
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
from pathlib import Path
# --------------------- Settings ---------------------
BASE_DIR = Path(__file__).resolve().parent
GESTURE_MODEL_PATH = str(BASE_DIR / "gesture_recognizer.task") # Path to the gesture model
SCORE_THRESHOLD = 0.5 # Show gestures above this score
# ---------------------------------------------------
# Initialize the Hands model (kept for landmark drawing)
hands = mp_hands.Hands(
static_image_mode=False,
max_num_hands=2,
min_detection_confidence=0.5
)
# Initialize Gesture Recognizer (VIDEO mode for streaming)
BaseOptions = python.BaseOptions
GestureRecognizerOptions = vision.GestureRecognizerOptions
RunningMode = vision.RunningMode
base_options = BaseOptions(model_asset_path=GESTURE_MODEL_PATH)
gr_options = GestureRecognizerOptions(
base_options=base_options,
running_mode=RunningMode.VIDEO
)
recognizer = vision.GestureRecognizer.create_from_options(gr_options)
# Open the camera
picam2 = Picamera2()
config = picam2.create_preview_configuration(
main={"size": (640, 480), "format": "XRGB8888"} ,
)
picam2.configure(config)
picam2.start()
print("Streaming... press 'q' to quit")
# (Optional) helper to draw a label near a hand bounding box computed from landmarks
def draw_gesture_label(frame_bgr, norm_landmarks, text, color=(0, 175, 255)):
"""
norm_landmarks: list of 21 normalized landmarks (x,y in [0,1]).
We compute a tight bbox to place the gesture text.
"""
if not norm_landmarks:
return
h, w = frame_bgr.shape[:2]
xs = [int(lm.x * w) for lm in norm_landmarks]
ys = [int(lm.y * h) for lm in norm_landmarks]
x1, y1 = max(0, min(xs)), max(0, min(ys))
x2, y2 = min(w-1, max(xs)), min(h-1, max(ys))
cv2.rectangle(frame_bgr, (x1, y1), (x2, y2), color, 1)
(tw, th), _ = cv2.getTextSize(text, cv2.FONT_HERSHEY_SIMPLEX, 0.7, 2)
y_text = max(0, y1 - th - 6)
cv2.rectangle(frame_bgr, (x1, y_text), (x1 + tw + 6, y_text + th + 6), color, -1)
cv2.putText(frame_bgr, text, (x1 + 3, y_text + th + 2),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,0,0), 2, cv2.LINE_AA)
while True:
frame_bgra = picam2.capture_array() # XRGB8888 to BGRA
frame_bgr = cv2.cvtColor(frame_bgra, cv2.COLOR_BGRA2BGR)
# Convert the frame from BGR to RGB (required by MediaPipe)
frame_rgb = cv2.cvtColor(frame_bgr, cv2.COLOR_BGR2RGB)
# ---- A) Run legacy Hands (for landmark drawing you already have) ----
hands_detected = hands.process(frame_rgb)
# ---- B) Run Gesture Recognizer (direct gesture labels) ----
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=frame_rgb)
ts_ms = int((cv2.getTickCount() / cv2.getTickFrequency()) * 1000)
gesture_result = recognizer.recognize_for_video(mp_image, ts_ms)
# Convert the frame back from RGB to BGR (required by OpenCV)
frame = cv2.cvtColor(frame_rgb, cv2.COLOR_RGB2BGR)
# If hands are detected, draw landmarks and connections on the frame
if hands_detected.multi_hand_landmarks:
for hand_landmarks in hands_detected.multi_hand_landmarks:
drawing.draw_landmarks(
frame,
hand_landmarks,
mp_hands.HAND_CONNECTIONS,
drawing_styles.get_default_hand_landmarks_style(),
drawing_styles.get_default_hand_connections_style(),
)
# ---- C) Overlay gesture names on top of each detected hand ----
if gesture_result and getattr(gesture_result, "gestures", None):
for i, gesture_list in enumerate(gesture_result.gestures):
if not gesture_list:
continue
top = gesture_list[0]
label = top.category_name # e.g., "Thumb_Up"
score = top.score or 0.0
if score < SCORE_THRESHOLD:
continue
hand_label = ""
if gesture_result.handedness and i < len(gesture_result.handedness):
if gesture_result.handedness[i]:
hand_label = gesture_result.handedness[i][0].category_name or ""
text = f"{hand_label} {label} ({score:.2f})".strip()
hand_lms = None
if gesture_result.hand_landmarks and i < len(gesture_result.hand_landmarks):
hand_lms = gesture_result.hand_landmarks[i]
if hand_lms:
draw_gesture_label(frame, hand_lms, text)
else:
cv2.putText(frame, text, (20, 40 + 30*i),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 175, 255), 2, cv2.LINE_AA)
# Display the frame with annotations
cv2.imshow("Show Video", frame)
if cv2.waitKey(1) & 0xff == ord('q'):
break
# Release the camera
try:
picam2.stop_preview()
except Exception:
pass
picam2.stop()
cv2.destroyAllWindows()
Nach dem Ausführen des Skripts zeigt das Fenster das Hand-Skelett (optional) und Gesten-Textfelder an. Wenn eine Geste erkannt wird, die zu den Kategorien des Modells passt, wird sie über der Begrenzungsbox der entsprechenden Hand angezeigt:
Linke/Rechte Hand (Händigkeit)
Gestenname (z. B.
Thumb_Up)Konfidenzwert (0~1)
6. Code-Erklärung
Dieses Beispiel kombiniert zwei Teile:
Hands (Solutions API): wird zum Zeichnen des Hand-Skeletts verwendet (21 Landmarks + Verbindungen).
Gesture Recognizer (Tasks API): wird zur Vorhersage eines Gestenlabels wie
Thumb_UpoderOpen_Palmverwendet.
Ablauf auf hoher Ebene
Initialisierung von Hands für das Zeichnen der Landmarks (optional, aber hilfreich für die Visualisierung).
Laden des Gesture-Recognizer-Modells (
gesture_recognizer.task) und Aktivieren desVIDEO-Modus.Starten der Kamera und Verarbeiten der Frames in einer Schleife:
Konvertieren des Frames in RGB (MediaPipe benötigt RGB).
Ausführen von Hands zum Zeichnen des Skeletts.
Ausführen des Gesture Recognizers, um
label + scorefür jede Hand zu erhalten.Zeichnen des Labels in der Nähe der entsprechenden Hand.
Drücken Sie
q, um das Programm zu beenden und Ressourcen freizugeben.
Wichtige Punkte zum Verständnis
Modelldatei
Der Gesture Recognizer benötigt
gesture_recognizer.task. Stellen Sie sicher, dass sich die Modelldatei im selben Ordner wie das Skript befindet (oder passen Sie den Pfad entsprechend an).VIDEO-Modus erfordert Zeitstempel
recognize_for_video()benötigt einen kontinuierlich ansteigenden Zeitstempel in Millisekunden. In diesem Beispiel wird er mithilfe der OpenCV-Tick-Zeit erzeugt.Anzeigen von Labels mit Konfidenzschwelle
Es werden nur Gesten mit einem Score >=
SCORE_THRESHOLDangezeigt. Dadurch wird vermieden, instabile Vorhersagen darzustellen.
7. Parameter und Feinabstimmung
Parameter |
Beschreibung |
Empfehlung |
|---|---|---|
|
Gesten unterhalb dieses Scores werden ignoriert |
Erhöhen, um Fehlalarme zu reduzieren; verringern, um die Erkennungsrate zu erhöhen |
|
Anzahl der gleichzeitig zu erkennenden Hände |
2 ist für die meisten Szenarien ausreichend |
|
Videostream-Modus, benötigt Zeitstempel |
Beibehalten (Streaming-Erkennung ist stabiler) |
Resolution |
Beeinflusst Geschwindigkeit und Genauigkeit |
Auf dem Raspberry Pi werden 640×480 oder niedriger für bessere FPS empfohlen |
8. Fehlerbehebung
FileNotFoundError: gesture_recognizer.taskDies bedeutet in der Regel, dass der Pfad zur Modelldatei falsch ist. Stellen Sie sicher, dass sich die Modelldatei im selben Verzeichnis wie das Skript befindet, oder passen Sie
GESTURE_MODEL_PATHentsprechend an.ImportError: cannot import name 'vision'Dieser Fehler weist darauf hin, dass die MediaPipe-Version veraltet ist. Aktualisieren Sie MediaPipe auf Version 0.10 oder neuer mit:
pip install --upgrade mediapipeErkannte Kategorie entspricht nicht der Erwartung
Der Kategoriensatz des Modells kann unterschiedlich sein, oder die Lichtverhältnisse können die Erkennung beeinflussen. Versuchen Sie, die Beleuchtung zu verbessern, den Hintergrund zu vereinfachen oder eine andere Modellversion zu verwenden.
Niedrige Bildrate
Die Leistung des Raspberry Pi kann begrenzt sein. Reduzieren Sie die Auflösung, deaktivieren Sie das Zeichnen des Skeletts oder schließen Sie unnötige Hintergrundprozesse.
9. Zusammenfassung
Gesture Recognizer ermöglicht semantische Gestenerkennung in Echtzeit auf dem Raspberry Pi;
In Kombination mit der Hands-Skelettdarstellung ist die Darstellung intuitiv und leicht zu debuggen;
Durch Anpassung von Schwellenwerten und Auflösung lässt sich ein Gleichgewicht zwischen „Stabilität / Geschwindigkeit“ erreichen;
Zukünftige Möglichkeiten:
Verschiedene Gesten bestimmten Befehlen zuordnen (Shortcuts, GPIO-Steuerung usw.);
Eigene Gestenmodelle für spezifische Anwendungsszenarien trainieren.