Nota
Ciao, benvenuto nella SunFounder Raspberry Pi & Arduino & ESP32 Enthusiasts Community su Facebook! Scopri di più su Raspberry Pi, Arduino e ESP32 insieme ad altri appassionati.
Perché unirti a noi?
Supporto Esperto: Risolvi problemi post-vendita e sfide tecniche con l’aiuto della nostra comunità e del nostro team.
Impara e Condividi: Scambia suggerimenti e tutorial per migliorare le tue competenze.
Anteprime Esclusive: Accedi in anteprima agli annunci di nuovi prodotti e alle anticipazioni.
Sconti Speciali: Approfitta di sconti esclusivi sui nostri prodotti più recenti.
Promozioni e Giveaway Festivi: Partecipa a giveaway e promozioni in occasione delle festività.
👉 Sei pronto a esplorare e creare con noi? Clicca [here] e unisciti oggi stesso!
17. Visione Testuale e Conversazione con Ollama
In questa lezione imparerai a usare Ollama, uno strumento per eseguire localmente modelli linguistici e visivi di grandi dimensioni. Ti mostreremo come installare Ollama, scaricare un modello e collegare PiCar-X ad esso.
Con questa configurazione, PiCar-X può scattare un’istantanea con la fotocamera e il modello potrà vedere e raccontare — potrai fare qualsiasi domanda sull’immagine e il modello risponderà in linguaggio naturale.
Prima di iniziare
Assicurati di aver completato:
Installare Tutti i Moduli (Importante) — Installa i moduli
robot-hat,vilib,picar-x, poi esegui lo scripti2samp.sh.
1. Installare Ollama (LLM) e Scaricare un Modello
Puoi scegliere dove installare Ollama:
Sul tuo Raspberry Pi (esecuzione locale)
Oppure su un altro computer (Mac/Windows/Linux) nella stessa rete locale
Modelli consigliati vs hardware
Puoi scegliere qualsiasi modello disponibile su Ollama Hub. I modelli sono disponibili in varie dimensioni (3B, 7B, 13B, 70B…). I modelli più piccoli sono più veloci e richiedono meno memoria, mentre quelli più grandi offrono migliore qualità ma richiedono hardware più potente.
Consulta la tabella seguente per decidere quale dimensione del modello si adatta al tuo dispositivo.
Dimensione modello |
RAM minima richiesta |
Hardware consigliato |
|---|---|---|
~3B parametri |
8GB (meglio 16GB) |
Raspberry Pi 5 (16GB) o PC/Mac di fascia media |
~7B parametri |
16GB+ |
Pi 5 (16GB, appena utilizzabile) o PC/Mac di fascia media |
~13B parametri |
32GB+ |
Desktop PC / Mac con molta RAM |
30B+ parametri |
64GB+ |
Workstation / Server / GPU consigliata |
70B+ parametri |
128GB+ |
Server di fascia alta con più GPU |
Installazione su Raspberry Pi
Se desideri eseguire Ollama direttamente sul tuo Raspberry Pi:
Usa una Raspberry Pi OS a 64 bit
Altamente consigliato: Raspberry Pi 5 (16GB RAM)
Esegui i seguenti comandi:
# Installa Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Scarica un modello leggero (utile per i test)
ollama pull llama3.2:3b
# Test veloce (digita 'hi' e premi Invio)
ollama run llama3.2:3b
# Avvia il server API (porta predefinita 11434)
# Suggerimento: imposta OLLAMA_HOST=0.0.0.0 per consentire l’accesso dalla LAN
OLLAMA_HOST=0.0.0.0 ollama serve
Installazione su Mac / Windows / Linux (App Desktop)
Scarica e installa Ollama da Ollama Download Page

Apri l’app Ollama, vai su Model Selector e usa la barra di ricerca per trovare un modello. Ad esempio, digita
llama3.2:3b(un modello piccolo e leggero per iniziare).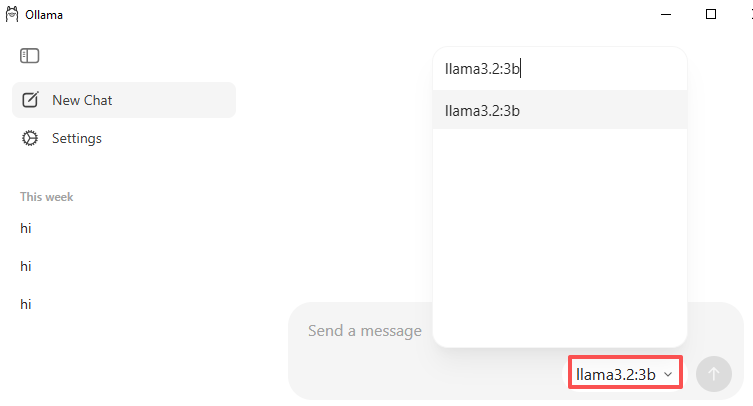
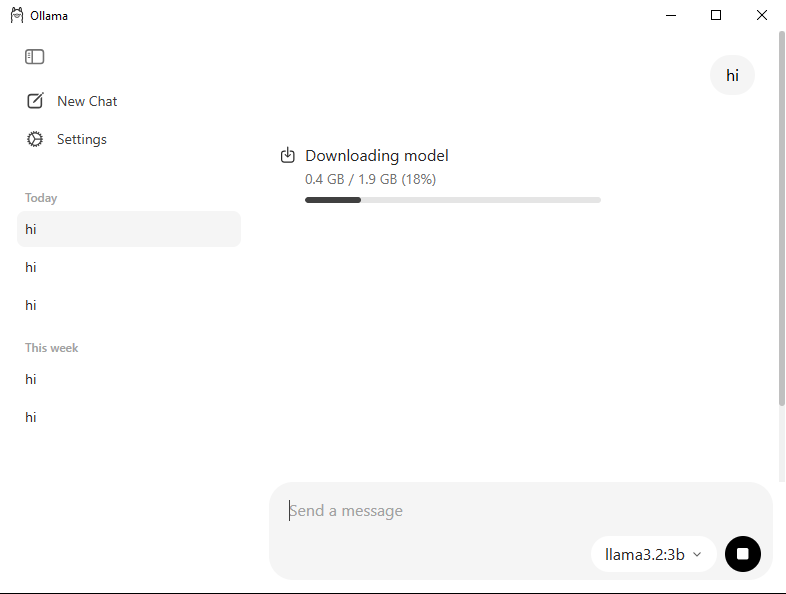
Dopo aver completato il download, digita qualcosa di semplice come “Hi” nella finestra di chat. Ollama inizierà automaticamente a scaricare il modello al primo utilizzo.
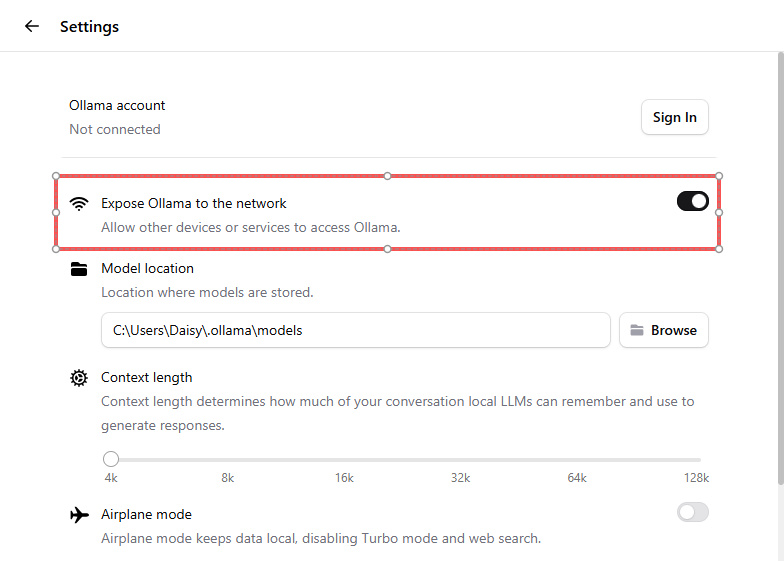
Vai su Settings → abilita Expose Ollama to the network. Questo consente al tuo Raspberry Pi di connettersi tramite LAN.
Avvertimento
Se vedi un errore come:
Error: model requires more system memory ...
significa che il modello è troppo grande per la tua macchina. Usa un modello più piccolo oppure passa a un computer con più RAM.
2. Testare Ollama
Una volta installato Ollama e pronto il tuo modello, puoi eseguire rapidamente un test con un semplice ciclo di chat minimale.
Passaggi
Crea un nuovo file:
cd ~/picar-x/example nano test_llm_ollama.py
Incolla il seguente codice e salva (
Ctrl+X→Y→Enter):from picarx.llm import Ollama INSTRUCTIONS = "You are a helpful assistant." WELCOME = "Hello, I am a helpful assistant. How can I help you?" # If Ollama runs on the same Raspberry Pi, use "localhost". # If it runs on another computer in your LAN, replace with that computer's IP address. llm = Ollama( ip="localhost", model="llama3.2:3b" # you can replace with any model ) # Basic configuration llm.set_max_messages(20) llm.set_instructions(INSTRUCTIONS) llm.set_welcome(WELCOME) print(WELCOME) while True: text = input(">>> ") if text.strip().lower() in {"exit", "quit"}: break # Response with streaming output response = llm.prompt(text, stream=True) for token in response: if token: print(token, end="", flush=True) print("")
Esegui il programma:
python3 test_llm_ollama.pyOra puoi chattare con PiCar-X direttamente dal terminale.
Puoi scegliere qualsiasi modello disponibile su Ollama Hub, ma si consigliano modelli più piccoli (ad es.
moondream:1.8b,phi3:mini) se disponi solo di 8–16GB di RAM.Assicurati che il modello specificato nel codice corrisponda esattamente a quello che hai già scaricato in Ollama.
Digita
exitoquitper interrompere il programma.Se non riesci a connetterti, verifica che Ollama sia in esecuzione e che entrambi i dispositivi siano sulla stessa LAN se usi un host remoto.
3. Vision Talk con Ollama
In questa demo, la fotocamera Pi scatta un’istantanea ogni volta che digiti una domanda. Il programma invia il testo digitato + la nuova foto a un modello visivo locale tramite Ollama e poi trasmette in streaming la risposta del modello in inglese semplice. Si tratta di una base minima “see & tell” che potrai in seguito estendere con controlli su colore/volto/QR.
Prima di iniziare
Apri l’app Ollama (o esegui il servizio) e assicurati di aver scaricato un modello compatibile con la visione.
Se hai abbastanza memoria (≥16GB RAM), puoi provare
llava:7b.Se disponi solo di 8GB RAM, preferisci un modello più piccolo come
moondream:1.8bogranite3.2-vision:2b.
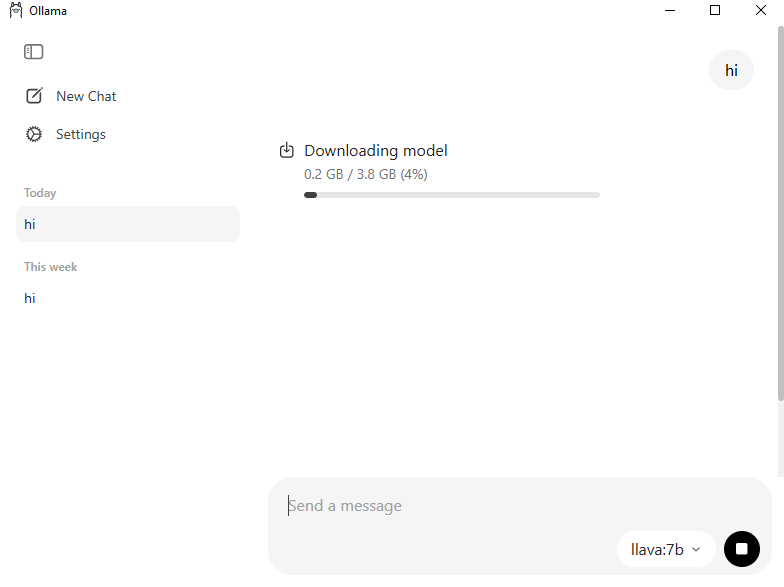
Esegui la Demo
Vai nella cartella degli esempi ed esegui lo script:
cd ~/picar-x/example python3 17.text_vision_talk.py
Cosa succede durante l’esecuzione:
Il programma stampa una riga di benvenuto e attende il tuo input (
>>>).Ogni volta che digiti qualcosa (es. “ciao”, “C’è qualcosa di giallo?”, “Ci sono volti?”, “Cosa c’è sulla scrivania?”), il programma:
cattura una foto dalla fotocamera Pi (salvata in
/tmp/llm-img.jpg),invia il tuo testo + la foto al modello visivo tramite Ollama,
trasmette in streaming la risposta del modello al terminale.
Digita
exitoquitper terminare il programma.
Codice
from picarx.llm import Ollama
from picamera2 import Picamera2
import time
"""
You need to set up Ollama first.
Note: At least 8GB RAM is recommended for small vision models (e.g., moondream:1.8b).
For llava:7b, more memory is preferred (≥16GB).
"""
INSTRUCTIONS = "You are a helpful assistant."
WELCOME = "Hello, I am a helpful assistant. How can I help you?"
# If Ollama runs on the same Pi, use "localhost".
# If it runs on another computer in your LAN, replace with that computer's IP.
llm = Ollama(
ip="localhost", # e.g., "192.168.100.145" if remote
model="llava:7b" # change to "moondream:1.8b" or "granite3.2-vision:2b" for 8GB RAM
)
# Basic configuration
llm.set_max_messages(20)
llm.set_instructions(INSTRUCTIONS)
llm.set_welcome(WELCOME)
# Init camera
camera = Picamera2()
config = camera.create_still_configuration(
main={"size": (1280, 720)},
)
camera.configure(config)
camera.start()
time.sleep(2)
print(WELCOME)
while True:
input_text = input(">>> ")
if input_text.strip().lower() in {"exit", "quit"}:
break
# Capture image
img_path = "/tmp/llm-img.jpg"
camera.capture_file(img_path)
# Response with stream (text + image)
response = llm.prompt(input_text, stream=True, image_path=img_path)
for next_word in response:
if next_word:
print(next_word, end="", flush=True)
print("")
Risoluzione dei Problemi
Ricevo un errore tipo: `model requires more system memory …`.
Significa che il modello è troppo grande per il tuo dispositivo.
Usa un modello più piccolo come
moondream:1.8bogranite3.2-vision:2b.Oppure passa a un computer con più RAM ed esponi Ollama alla rete.
Il codice non riesce a connettersi a Ollama (connection refused).
Controlla i seguenti punti:
Assicurati che Ollama sia in esecuzione (
ollama serveo che l’app desktop sia aperta).Se utilizzi un computer remoto, abilita Expose to network nelle impostazioni di Ollama.
Verifica che l’indirizzo
ip="..."nel tuo codice corrisponda all’indirizzo IP LAN corretto.Controlla che entrambi i dispositivi si trovino nella stessa rete locale.
La fotocamera Pi non cattura nulla.
Verifica che
Picamera2sia installato e funzionante con uno script di test semplice.Controlla che il cavo della fotocamera sia correttamente collegato e abilitato in
raspi-config.Assicurati che lo script abbia i permessi per scrivere nel percorso di destinazione (
/tmp/llm-img.jpg).
L’output è troppo lento.
I modelli più piccoli rispondono più velocemente, ma con risposte più semplici.
Puoi ridurre la risoluzione della fotocamera (es. 640×480 invece di 1280×720) per velocizzare l’elaborazione.
Chiudi altri programmi sul tuo Pi per liberare CPU e RAM.