Bemerkung
Hallo, willkommen in der SunFounder Raspberry Pi & Arduino & ESP32 Enthusiasts Community auf Facebook! Tauchen Sie gemeinsam mit anderen Enthusiasten tiefer in Raspberry Pi, Arduino und ESP32 ein.
Warum mitmachen?
Experten-Support : Lösen Sie After-Sales-Probleme und technische Herausforderungen mit Hilfe unserer Community und unseres Teams.
Lernen & Teilen : Tauschen Sie Tipps und Tutorials aus, um Ihre Fähigkeiten zu verbessern.
Exklusive Vorschauen : Erhalten Sie frühzeitigen Zugriff auf neue Produktankündigungen und exklusive Einblicke.
Sonderrabatte : Profitieren Sie von exklusiven Rabatten auf unsere neuesten Produkte.
Festliche Aktionen und Gewinnspiele : Nehmen Sie an Gewinnspielen und saisonalen Aktionen teil.
👉 Bereit, mit uns zu entdecken und zu erschaffen? Klicken Sie auf [here] und treten Sie noch heute bei!
2. TTS mit Piper und OpenAI
In der vorherigen Lektion haben wir Espeak und Pico2Wave untersucht, zwei einfache Offline-TTS-Engines auf dem Raspberry Pi. Jetzt machen wir einen großen Schritt nach vorn und probieren zwei fortgeschrittenere TTS-Optionen aus, die höhere Sprachqualität und mehr Flexibilität bieten:
Piper — eine schnelle, auf neuronalen Netzen basierende TTS-Engine, die auf dem Raspberry Pi vollständig offline läuft.
OpenAI TTS — ein Online-Dienst, der sehr natürliche und menschenähnliche Stimmen bereitstellt — perfekt für ausdrucksstarke Sprache.
Diese Engines lassen Ihr Fusion HAT+ realistischer und lebendiger klingen. 🚀
1. Piper testen
Piper ist eine offline neuronale TTS-Engine, das heißt, Sie benötigen keine Internetverbindung mehr, sobald das Modell installiert ist. Es unterstützt mehrere Sprachen und Stimmen und ist damit eine leistungsstarke Option für eingebettete Sprachausgabe.
Programm ausführen
cd ~/fusion-hat/examples sudo python3 tts_piper.py
Beim ersten Ausführen wird das ausgewählte Stimmenmodell automatisch heruntergeladen.
Danach sollten Sie Fusion HAT+ sagen hören:
Hello! I'm Piper TTS.Sie können Stimmen oder Sprachen wechseln, indem Sie
set_model()mit einem anderen Modellnamen aufrufen.
Code
from fusion_hat.tts import Piper
tts = Piper()
# List supported languages
print(tts.available_countrys())
# List models for English (en_us)
print(tts.available_models('en_us'))
# Set a voice model (auto-download if not already present)
tts.set_model("en_US-amy-low")
# Say something
tts.say("Hello! I'm Piper TTS.")
Code-Erklärung:
available_countrys()— Listet alle unterstützten Sprachen auf.available_models()— Listet verfügbare Modelle für eine bestimmte Sprache auf.set_model()— Legt das Stimmenmodell fest. Wenn das Modell nicht installiert ist, wird es automatisch heruntergeladen.say()— Wandelt Text in Sprache um und spielt sie sofort ab.
💡 Tipp: Probieren Sie verschiedene Modelle aus, um Geschwindigkeit, Klarheit und Akzente zu vergleichen. Einige Modelle sind leichter (schneller), während andere eine höhere Wiedergabetreue bieten.
2. OpenAI TTS testen
API-Schlüssel abrufen und speichern
Gehen Sie zu OpenAI Platform und melden Sie sich an. Klicken Sie auf der Seite API keys auf Create new secret key .
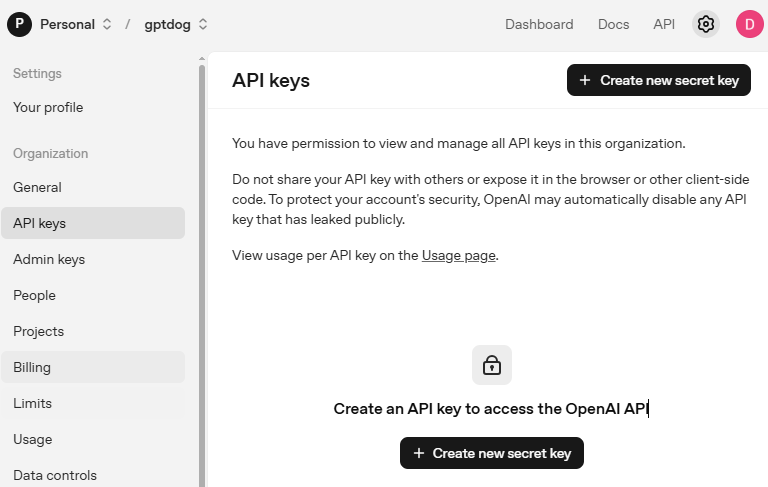
Füllen Sie die Details aus (Owner, Name, Project und bei Bedarf Berechtigungen), und klicken Sie dann auf Create secret key .
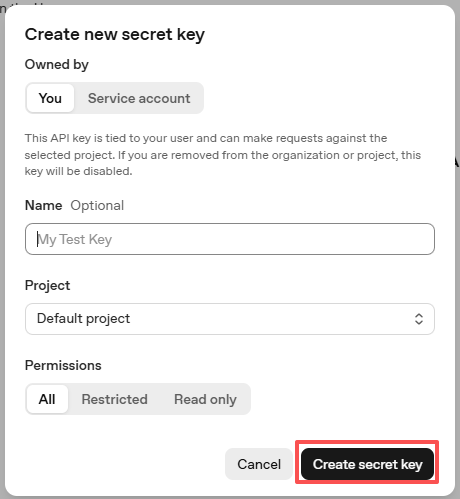
Sobald der Schlüssel erstellt wurde, kopieren Sie ihn sofort — Sie können ihn danach nicht mehr ansehen. Wenn Sie ihn verlieren, müssen Sie einen neuen erstellen.
Erstellen Sie in Ihrem Projektordner (zum Beispiel:
/) eine Datei mit dem Namensecret.py:cd ~/fusion-hat/examples sudo nano secret.py
Fügen Sie Ihren Schlüssel so in die Datei ein:
# secret.py # Store secrets here. Never commit this file to Git. OPENAI_API_KEY = "sk-xxx"
Programm ausführen
cd ~/fusion-hat/examples
sudo python3 tts_openai.py
Das Programm verbindet sich mit dem OpenAI-TTS-Dienst, und Fusion HAT+ spricht mit natürlicher, ausdrucksstarker Sprachausgabe .
Sie können Stimmstile ändern und instructions hinzufügen, um Tonfall und Ausdruck zu steuern (z. B. traurig, dramatisch, verspielt).
Dadurch eignet sich OpenAI TTS ideal für interaktive Roboter, Storytelling oder Lehrassistenten.
Code
from fusion_hat.tts import OpenAI_TTS
from secret import OPENAI_API_KEY
# Export your OpenAI_API_KEY before running the script
# export OPENAI_API_KEY="sk-proj-xxxxxx"
tts = OpenAI_TTS(api_key=OPENAI_API_KEY)
# tts.set_model('tts-1')
tts.set_voice('alloy')
tts.set_model('gpt-4o-mini-tts')
msg = "Hello! I'm OpenAI TTS."
print(f"Say: {msg}")
tts.say(msg)
msg = "with instructions, I can say word sadly"
instructions = "say it sadly"
print(f"Say: {msg}, with instructions: '{instructions}'")
tts.say(msg, instructions=instructions)
msg = "or say something dramaticly."
instructions = "say it dramaticly"
print(f"Say: {msg}, with instructions: '{instructions}'")
tts.say(msg, instructions=instructions)
Code-Erklärung:
OpenAI_TTS()— Initialisiert die OpenAI-TTS-Engine mit Ihrem API-Schlüssel.set_model()— Wählt das TTS-Modell aus (z. B.gpt-4o-mini-tts).set_voice()— Wählt eine bestimmte Stimme aus (z. B.alloy).say(text)— Wandelt den Text in Sprache um und spielt sie ab.say(text, instructions=...)— Fügt Anweisungen für ausdrucksstarken Tonfall hinzu, sodass Sie den Sprechstil dynamisch steuern können.
Beispiel:
„say it sadly“ → weicher, emotionaler Ton
„say it dramatically“ → kräftige und ausdrucksstarke Darbietung
„say it excitedly“ → begeisterter Ton
Fehlerbehebung
No module named ‚secret‘
Das bedeutet, dass sich
secret.pynicht im selben Ordner wie Ihre Python-Datei befindet. Verschieben Siesecret.pyin dasselbe Verzeichnis, in dem Sie das Skript ausführen, z. B.:ls ~/ # Make sure you see both: secret.py and your .py file
OpenAI: Ungültiger API-Schlüssel / 401
Prüfen Sie, ob Sie den vollständigen Schlüssel eingefügt haben (beginnt mit
sk-) und ob keine zusätzlichen Leerzeichen / Zeilenumbrüche vorhanden sind.Stellen Sie sicher, dass Ihr Code ihn korrekt importiert:
from secret import OPENAI_API_KEY
Bestätigen Sie den Netzwerkzugriff auf Ihrem Pi (testen Sie
ping api.openai.com).
OpenAI: Kontingent überschritten / Abrechnungsfehler
Möglicherweise müssen Sie die Abrechnung hinzufügen oder das Kontingent im OpenAI-Dashboard erhöhen.
Versuchen Sie es erneut, nachdem Sie das Konto- / Abrechnungsproblem behoben haben.
Piper: tts.say() läuft, aber kein Ton
Stellen Sie sicher, dass tatsächlich ein Stimmenmodell vorhanden ist:
ls ~/.local/share/piper/voicesBestätigen Sie, dass Ihr Modellname im Code exakt übereinstimmt:
tts.set_model("en_US-amy-low")
Prüfen Sie das Audio-Ausgabegerät / die Lautstärke auf Ihrem Pi (
alsamixer) und stellen Sie sicher, dass die Lautsprecher angeschlossen und eingeschaltet sind.
ALSA- / Soundgeräte-Fehler (z. B. „Audio device busy“ oder „No such file or directory“)
Schließen Sie andere Programme, die Audio verwenden.
Starten Sie den Pi neu, wenn das Gerät weiterhin belegt ist.
Für HDMI- vs. Kopfhörerbuchsen-Ausgabe wählen Sie das richtige Gerät in den Audioeinstellungen von Raspberry Pi OS aus.
Permission denied beim Ausführen von Python
Versuchen Sie es mit
sudo, wenn Ihre Umgebung dies erfordert:sudo python3 tts_piper.py
Vergleich von TTS-Engines
Element |
Espeak |
Pico2Wave |
Piper |
OpenAI TTS |
|---|---|---|---|---|
Läuft auf |
In Raspberry Pi integriert ( offline ) |
In Raspberry Pi integriert ( offline ) |
Raspberry Pi / PC ( offline, benötigt Modell ) |
Cloud ( online, benötigt API-Schlüssel ) |
Sprachqualität |
Robotisch |
Natürlicher als Espeak |
Natürlich ( neuronales TTS ) |
Sehr natürlich / menschenähnlich |
Steuerung |
Geschwindigkeit, Tonhöhe, Lautstärke |
Eingeschränkte Steuerung |
Verschiedene Stimmen / Modelle wählen |
Modell und Stimmen wählen |
Sprachen |
Viele ( Qualität variiert ) |
Begrenzter Umfang |
Viele Stimmen / Sprachen verfügbar |
Am besten auf Englisch ( andere variieren je nach Verfügbarkeit ) |
Latenz / Geschwindigkeit |
Sehr schnell |
Schnell |
Echtzeit auf Pi 4/5 mit „low“-Modellen |
Netzwerkabhängig ( normalerweise geringe Latenz ) |
Einrichtung |
Minimal |
Minimal |
|
API-Schlüssel erstellen, Client installieren |
Am besten geeignet für |
Schnelle Tests, einfache Prompts |
Etwas bessere Offline-Stimme |
Lokale Projekte mit besserer Qualität |
Höchste Qualität, umfangreiche Stimmoptionen |