Bemerkung
Hallo, willkommen in der SunFounder Raspberry Pi & Arduino & ESP32 Enthusiasts Community auf Facebook! Tauchen Sie gemeinsam mit anderen Enthusiasten tiefer in Raspberry Pi, Arduino und ESP32 ein.
Warum mitmachen?
Experten-Support : Lösen Sie After-Sales-Probleme und technische Herausforderungen mit Hilfe unserer Community und unseres Teams.
Lernen & Teilen : Tauschen Sie Tipps und Tutorials aus, um Ihre Fähigkeiten zu verbessern.
Exklusive Vorschauen : Erhalten Sie frühzeitigen Zugriff auf neue Produktankündigungen und exklusive Einblicke.
Sonderrabatte : Profitieren Sie von exklusiven Rabatten auf unsere neuesten Produkte.
Festliche Aktionen und Gewinnspiele : Nehmen Sie an Gewinnspielen und saisonalen Aktionen teil.
👉 Bereit, mit uns zu entdecken und zu erschaffen? Klicken Sie auf [here] und treten Sie noch heute bei!
4. Text-Vision-Talk mit Ollama
In dieser Lektion lernen Sie, wie Sie Ollama verwenden — ein Tool, um große Sprach- und Vision-Modelle lokal auszuführen. Wir zeigen Ihnen, wie Sie Ollama installieren, ein Modell herunterladen und Fusion HAT+ damit verbinden.
Mit diesem Setup kann Fusion HAT+ einen Kameraschnappschuss aufnehmen und das Modell wird sehen und beschreiben — Sie können jede Frage zum Bild stellen, und das Modell antwortet in natürlicher Sprache.
1. Ollama ( LLM ) installieren und Modell herunterladen
Sie können auswählen, wo Sie Ollama installieren :
Auf Ihrem Raspberry Pi ( lokal ausführen )
Oder auf einem anderen Computer ( Mac / Windows / Linux ) im gleichen lokalen Netzwerk
Empfohlene Modelle vs. Hardware
Sie können jedes Modell wählen, das auf Ollama Hub verfügbar ist. Modelle gibt es in verschiedenen Größen ( 3B, 7B, 13B, 70B … ). Kleinere Modelle laufen schneller und benötigen weniger Speicher, während größere Modelle eine bessere Qualität liefern, aber leistungsstarke Hardware erfordern.
Sehen Sie sich die Tabelle unten an, um zu entscheiden, welche Modellgröße zu Ihrem Gerät passt.
Modellgröße |
Min. benötigter RAM |
Empfohlene Hardware |
|---|---|---|
~3B Parameter |
8 GB ( 16 GB besser ) |
Raspberry Pi 5 ( 16 GB ) oder Mittelklasse-PC / Mac |
~7B Parameter |
16 GB+ |
Pi 5 ( 16 GB, gerade noch nutzbar ) oder Mittelklasse-PC / Mac |
~13B Parameter |
32 GB+ |
Desktop-PC / Mac mit viel RAM |
30B+ Parameter |
64 GB+ |
Workstation / Server / GPU empfohlen |
70B+ Parameter |
128 GB+ |
High-End-Server mit mehreren GPUs |
Auf Raspberry Pi installieren
Wenn Sie Ollama direkt auf Ihrem Raspberry Pi ausführen möchten :
Verwenden Sie ein 64-Bit Raspberry Pi OS
Dringend empfohlen : Raspberry Pi 5 ( 16 GB RAM )
Führen Sie die folgenden Befehle aus :
# Install Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Pull a lightweight model (good for testing)
ollama pull llama3.2:3b
# Quick run test (type 'hi' and press Enter)
ollama run llama3.2:3b
# Serve the API (default port 11434)
# Tip: set OLLAMA_HOST=0.0.0.0 to allow access from LAN
OLLAMA_HOST=0.0.0.0 ollama serve
Auf Mac / Windows / Linux installieren ( Desktop-App )
Laden Sie Ollama über Ollama Download Page herunter und installieren Sie es
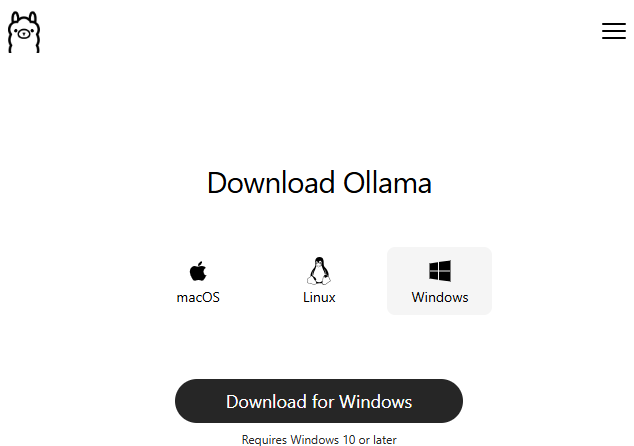
Öffnen Sie die Ollama-App, gehen Sie zum Model Selector und verwenden Sie die Suchleiste, um ein Modell zu finden. Tippen Sie z. B.
llama3.2:3bein ( ein kleines und leichtgewichtiges Modell für den Einstieg ).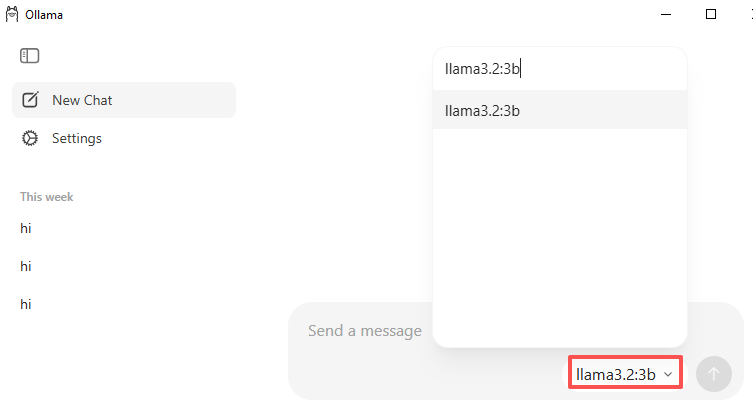
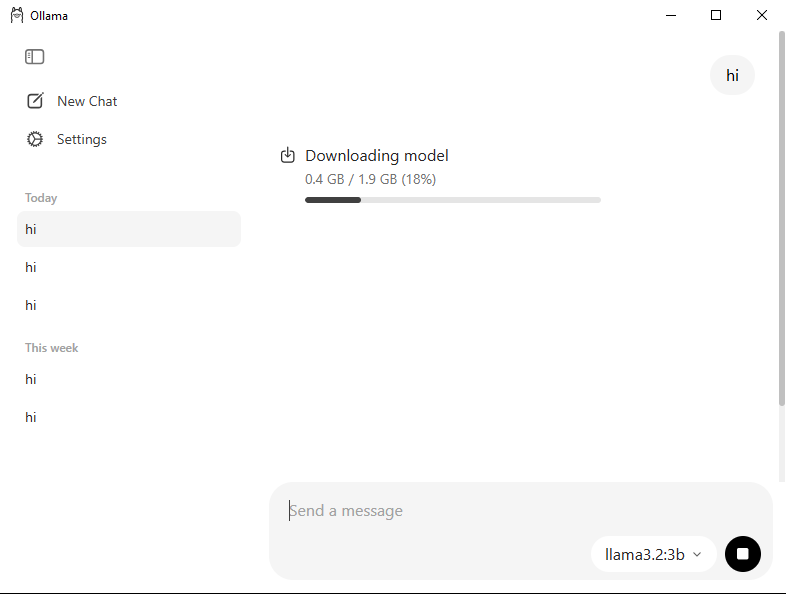
Nachdem der Download abgeschlossen ist, geben Sie im Chatfenster etwas Einfaches wie „Hi“ ein. Ollama startet den Download automatisch, wenn Sie das Modell zum ersten Mal verwenden.
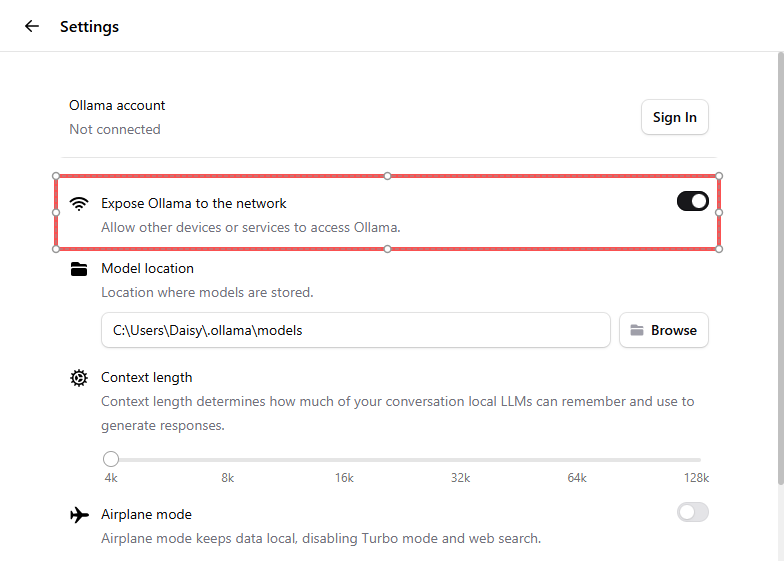
Gehen Sie zu Settings → aktivieren Sie Expose Ollama to the network . Dadurch kann sich Ihr Raspberry Pi über LAN damit verbinden.
Warnung
Wenn Sie einen Fehler sehen wie :
Error: model requires more system memory ...
Das Modell ist zu groß für Ihren Rechner. Verwenden Sie ein kleineres Modell oder wechseln Sie zu einem Computer mit mehr RAM.
2. Ollama testen
Sobald Ollama installiert ist und Ihr Modell bereit ist, können Sie es schnell mit einer minimalen Chat-Schleife testen.
Programm ausführen
cd ~/fusion-hat/examples sudo python3 llm_ollama.py
Jetzt können Sie direkt im Terminal mit Fusion HAT+ chatten.
Sie können jedes Modell wählen, das auf Ollama Hub verfügbar ist, aber kleinere Modelle ( z. B.
moondream:1.8b,phi3:mini) werden empfohlen, wenn Sie nur 8 – 16 GB RAM haben.Stellen Sie sicher, dass das im Code angegebene Modell mit dem Modell übereinstimmt, das Sie bereits in Ollama heruntergeladen haben.
Geben Sie
exitoderquitein, um das Programm zu beenden.Wenn keine Verbindung möglich ist, stellen Sie sicher, dass Ollama läuft und dass sich beide Geräte im gleichen LAN befinden, wenn Sie einen Remote-Host verwenden.
Code
from fusion_hat.llm import Ollama
INSTRUCTIONS = "You are a helpful assistant."
WELCOME = "Hello, I am a helpful assistant. How can I help you?"
# Change this to your computer IP, if you run it on your pi, then change it to localhost
llm = Ollama(
ip="localhost",
model="llama3.2:3b"
)
# Set how many messages to keep
llm.set_max_messages(20)
# Set instructions
llm.set_instructions(INSTRUCTIONS)
# Set welcome message
llm.set_welcome(WELCOME)
print(WELCOME)
while True:
input_text = input(">>> ")
# Response without stream
# response = llm.prompt(input_text)
# print(f"response: {response}")
# Response with stream
response = llm.prompt(input_text, stream=True)
for next_word in response:
if next_word:
print(next_word, end="", flush=True)
print("")
3. Vision-Talk mit Ollama
In dieser Demo macht die Pi-Kamera jedes Mal, wenn Sie eine Frage eingeben , einen Schnappschuss. Das Programm sendet Ihren eingegebenen Text + das neue Foto über Ollama an ein lokales Vision-Modell und streamt anschließend die Antwort des Modells in einfachem Englisch. Dies ist eine minimale „see & tell“-Basis, die Sie später mit Farb- / Gesichts- / QR-Prüfungen erweitern können.
Bevor Sie beginnen
Öffnen Sie die Ollama -App ( oder starten Sie den Dienst ) und stellen Sie sicher, dass ein Vision-fähiges Modell heruntergeladen ist.
Wenn Sie genügend Speicher ( ≥ 16 GB RAM ) haben, können Sie
llava:7bausprobieren.Wenn Sie nur 8 GB RAM haben, bevorzugen Sie ein kleineres Modell wie
moondream:1.8bodergranite3.2-vision:2b.
Demo ausführen
Wechseln Sie in den Beispielordner und führen Sie das Skript aus :
cd ~/fusion-hat/examples python3 llm_ollama_with_image.py
Was passiert beim Ausführen :
Das Programm gibt eine Begrüßungszeile aus und wartet auf Ihre Eingabe (
>>>).Jedes Mal, wenn Sie etwas eingeben ( z. B. „hello“, „Is there yellow?“, „Any faces?“, „What is on the desk?“ ), wird :
ein Foto aufgenommen von der Pi-Kamera ( gespeichert unter
/tmp/llm-img.jpg),Ihr Text + das Foto gesendet an das Vision-Modell über Ollama,
die Antwort des Modells gestreamt zurück ins Terminal.
Geben Sie
exitoderquitein, um das Programm zu beenden.
Code
from fusion_hat.llm import Ollama
from picamera2 import Picamera2
import time
'''
You need to setup ollama first, see llm_local.py
You need at leaset 8GB RAM to run llava:7b large multimodal model
'''
INSTRUCTIONS = "You are a helpful assistant."
WELCOME = "Hello, I am a helpful assistant. How can I help you?"
llm = Ollama(
ip="localhost", # e.g., "192.168.100.145" if remote
model="llava:7b" # change to "moondream:1.8b" or "granite3.2-vision:2b" for 8GB RAM
)
# Set how many messages to keep
llm.set_max_messages(20)
# Set instructions
llm.set_instructions(INSTRUCTIONS)
# Set welcome message
llm.set_welcome(WELCOME)
# Init camera
camera = Picamera2()
config = camera.create_still_configuration(
main={"size": (1280, 720)},
)
camera.configure(config)
camera.start()
time.sleep(2)
print(WELCOME)
while True:
input_text = input(">>> ")
# Capture image
img_path = '/tmp/llm-img.jpg'
camera.capture_file(img_path)
# Response without stream
# response = llm.prompt(input_text, image_path=img_path)
# print(f"response: {response}")
# Response with stream
response = llm.prompt(input_text, stream=True, image_path=img_path)
for next_word in response:
if next_word:
print(next_word, end="", flush=True)
print("")
Fehlerbehebung
Ich erhalte einen Fehler wie: `model requires more system memory …`.
Das bedeutet, dass das Modell zu groß für Ihr Gerät ist.
Verwenden Sie ein kleineres Modell wie
moondream:1.8bodergranite3.2-vision:2b.Oder wechseln Sie zu einem Rechner mit mehr RAM und geben Sie Ollama im Netzwerk frei.
Der Code kann keine Verbindung zu Ollama herstellen ( Verbindung verweigert ).
Prüfen Sie Folgendes :
Stellen Sie sicher, dass Ollama läuft (
ollama serveoder die Desktop-App ist geöffnet ).Wenn Sie einen Remote-Computer verwenden, aktivieren Sie Expose to network in den Ollama-Einstellungen.
Überprüfen Sie, ob
ip="..."in Ihrem Code mit der korrekten LAN-IP übereinstimmt.Bestätigen Sie, dass beide Geräte im gleichen lokalen Netzwerk sind.
Meine Pi-Kamera nimmt nichts auf.
Überprüfen Sie, ob
Picamera2installiert ist und mit einem einfachen Testskript funktioniert.Prüfen Sie, ob das Kamerakabel korrekt angeschlossen ist und in
raspi-configaktiviert wurde.Stellen Sie sicher, dass Ihr Skript Schreibrechte für den Zielpfad hat (
/tmp/llm-img.jpg).
Die Ausgabe ist zu langsam.
Kleinere Modelle antworten schneller, liefern aber einfachere Antworten.
Sie können die Kameraauflösung verringern ( z. B. 640×480 statt 1280×720 ), um die Bildverarbeitung zu beschleunigen.
Schließen Sie andere Programme auf Ihrem Pi, um CPU und RAM freizugeben.