注釈
こんにちは、SunFounder Raspberry Pi & Arduino & ESP32 Enthusiasts Community on Facebookへようこそ! Raspberry Pi、Arduino、ESP32について、愛好家仲間とより深く探求しましょう。
参加する理由
専門家によるサポート: コミュニティとチームの助けを借りて、アフターセールスの問題や技術的な課題を解決します。
学びと共有: ヒントやチュートリアルを交換して、スキルを向上させましょう。
先行プレビュー: 新製品の発表や先行情報をいち早く入手できます。
特別割引: 新製品の限定割引をお楽しみいただけます。
お祭りプロモーションとプレゼント: プレゼントキャンペーンやホリデープロモーションに参加しましょう。
👉 私たちと一緒に探求し、創造する準備はできましたか? [here] をクリックして、今すぐ参加しましょう!
2. PiperとOpenAIによるTTS
前のレッスンでは、Raspberry Pi上の2つのシンプルなオフラインTTSエンジンである Espeak と Pico2Wave を探求しました。 ここでは、より 高度なTTSオプション にステップアップし、より高音質 で柔軟性の高い2つの方法を試してみましょう:
Piper — Raspberry Pi上で 完全にオフライン 動作する、高速なニューラルネットワークベースのTTSエンジン。
OpenAI TTS — 非常に自然で人間らしい声 を提供するオンラインサービス。表現力豊かな音声に最適です。
これらのエンジンにより、Pironman 5 Pro MAX の音声がよりリアルで生き生きとします。🚀
1. Piperのテスト
Piperは オフラインのニューラルTTSエンジン です。モデルがインストールされていればインターネット接続は必要ありません。 複数の 言語 と 音声 をサポートしており、組み込み用途での強力な選択肢となります。
プログラムの実行
cd ~/sunfounder-voice-assistant/examples sudo python3 tts_piper.py
初回実行時には、選択された 音声モデル が自動的にダウンロードされます。
その後、Pironman 5 Pro MAX が
Hello! I'm Piper TTS.と話すのが聞こえます。異なるモデル名を指定して
set_model()を呼び出すことで、音声や言語を切り替えることができます。
コード
from sunfounder_voice_assistant.tts import Piper
tts = Piper()
# サポートされている言語を一覧表示
print(tts.available_countrys())
# 英語(en_us)のモデルを一覧表示
print(tts.available_models('en_us'))
# 音声モデルを設定(存在しない場合は自動ダウンロード)
tts.set_model("en_US-amy-low")
# 発話
tts.say("Hello! I'm Piper TTS.")
コードの説明:
available_countrys()— サポートされているすべての言語を一覧表示します。available_models()— 特定の言語で利用可能なモデルを一覧表示します。set_model()— 音声モデルを設定します。モデルがインストールされていない場合は自動的にダウンロードされます。say()— テキストを音声に変換し、すぐに再生します。
💡 ヒント: 異なるモデルを試して、速度、明瞭さ、アクセントを比較してみてください。軽量なモデル(高速)もあれば、高忠実度のモデルもあります。
2. OpenAI TTSのテスト
APIキーの取得と保存
OpenAI Platform にアクセスしてログインします。 API keys ページで、 Create new secret key をクリックします。
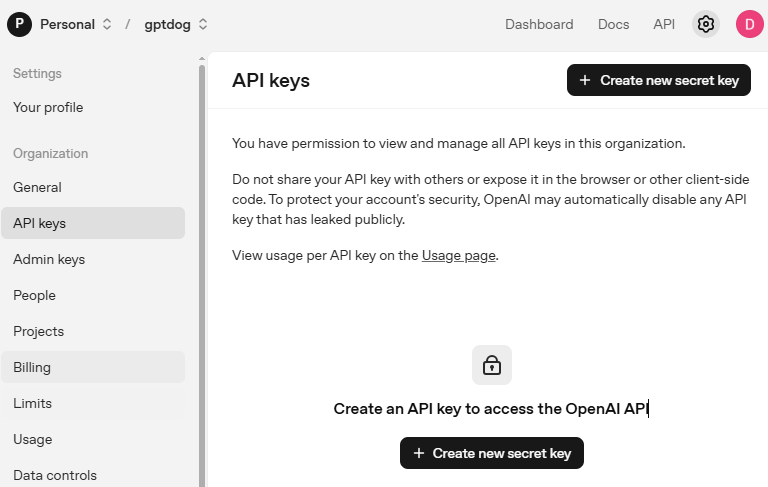
詳細情報(Owner、Name、Project、必要に応じて権限)を入力し、 Create secret key をクリックします。
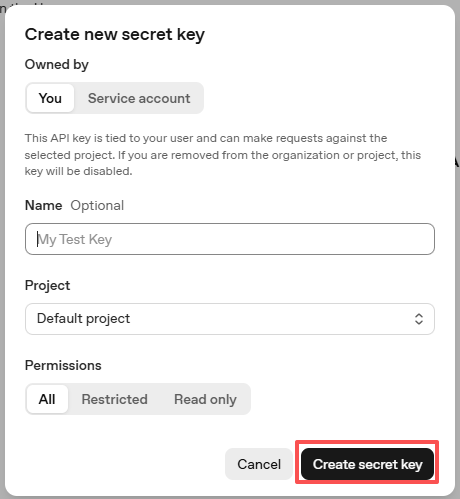
キーが作成されたら、すぐにコピーします — 二度と表示することはできません。紛失した場合は、新しいキーを生成する必要があります。
プロジェクトフォルダ内(例:
/)に、secret.pyというファイルを作成します:cd ~/sunfounder-voice-assistant/examples sudo nano secret.py
以下のようにキーをファイルに貼り付けます:
# secret.py # シークレット情報をここに保存します。このファイルをGitにコミットしないでください。 OPENAI_API_KEY = "sk-xxx"
プログラムの実行
cd ~/sunfounder-voice-assistant/examples
sudo python3 tts_openai.py
プログラムはOpenAIのTTSサービスに接続し、Pironman 5 Pro MAX は 自然で表現力豊かな音声 で話します。
音声スタイル を変更したり、 指示文 を追加してトーンや表現を制御できます(例:悲しげ、劇的に、遊び心を持って)。
これにより、OpenAI TTSはインタラクティブなロボット、ストーリーテリング、教育アシスタントに最適です。
コード
from sunfounder_voice_assistant.tts import OpenAI_TTS
from secret import OPENAI_API_KEY
# スクリプト実行前に OpenAI_API_KEY をエクスポートしてください
# export OPENAI_API_KEY="sk-proj-xxxxxx"
tts = OpenAI_TTS(api_key=OPENAI_API_KEY)
# tts.set_model('tts-1')
tts.set_voice('alloy')
tts.set_model('gpt-4o-mini-tts')
msg = "Hello! I'm OpenAI TTS."
print(f"Say: {msg}")
tts.say(msg)
msg = "with instructions, I can say word sadly"
instructions = "say it sadly"
print(f"Say: {msg}, with instructions: '{instructions}'")
tts.say(msg, instructions=instructions)
msg = "or say something dramaticly."
instructions = "say it dramaticly"
print(f"Say: {msg}, with instructions: '{instructions}'")
tts.say(msg, instructions=instructions)
コードの説明:
OpenAI_TTS()— APIキーを使用してOpenAI TTSエンジンを初期化します。set_model()— TTSモデルを選択します(例:gpt-4o-mini-tts)。set_voice()— 特定の音声を選択します(例:alloy)。say(text)— テキストを音声に変換して再生します。say(text, instructions=...)— 表現力豊かなトーンの指示文 を追加し、音声スタイルを動的に制御できます。
例:
「say it sadly」 → 柔らかく、感情的なトーン
「say it dramatically」 → 大胆で表現豊かな話し方
「say it excitedly」 → 熱意のあるトーン
トラブルシューティング
No module named 'secret'
secret.pyがPythonファイルと同じフォルダにないことを意味します。secret.pyをスクリプトを実行するディレクトリに移動します。例:ls ~/ # secret.py と .py ファイルの両方が表示されることを確認してください
OpenAI: Invalid API key / 401
完全なキー(
sk-で始まる)を貼り付け、余分なスペースや改行がないことを確認します。コードで正しくインポートされていることを確認します:
from secret import OPENAI_API_KEY
Pi上のネットワークアクセスを確認します(
ping api.openai.comを試してください)。
OpenAI: Quota exceeded / billing error
OpenAIダッシュボードで請求情報を追加するか、割り当て量を増やす必要がある場合があります。
アカウント/請求の問題を解決した後、再度お試しください。
Piper: tts.say() は実行されるが音が出ない
音声モデルが実際に存在することを確認します:
ls ~/.local/share/piper/voicesコード内のモデル名が完全に一致していることを確認します:
tts.set_model("en_US-amy-low")
Piの音声出力デバイス/音量を確認し(
alsamixer)、スピーカーが接続され電源が入っていることを確認します。
ALSA / サウンドデバイスのエラー(例:「Audio device busy」または「No such file or directory」)
オーディオを使用している他のプログラムを終了します。
デバイスがビジー状態のままの場合はPiを再起動します。
HDMIとヘッドフォンジャックの出力の場合は、Raspberry Pi OSのオーディオ設定で正しいデバイスを選択します。
Python実行時の Permission denied
環境で必要な場合は
sudoを付けて試します:sudo python3 tts_piper.py
TTSエンジンの比較
項目 |
Espeak |
Pico2Wave |
Piper |
OpenAI TTS |
|---|---|---|---|---|
実行環境 |
Raspberry Pi 組み込み(オフライン) |
Raspberry Pi 組み込み(オフライン) |
Raspberry Pi / PC(オフライン、モデル必要) |
クラウド(オンライン、APIキー必要) |
音声品質 |
ロボット的 |
Espeakより自然 |
自然(ニューラルTTS) |
非常に自然/人間らしい |
制御 |
速度、ピッチ、音量 |
制限あり |
異なる音声/モデルを選択 |
モデルと音声を選択 |
言語 |
多数(品質は様々) |
限定的 |
多数の音声/言語が利用可能 |
英語が最適(他は提供状況により異なる) |
遅延/速度 |
非常に高速 |
高速 |
Pi 4/5で「低」モデルならリアルタイム |
ネットワーク依存(通常は低遅延) |
セットアップ |
最小限 |
最小限 |
|
APIキー作成、クライアントインストール |
最適な用途 |
簡単なテスト、基本的なプロンプト |
少し良いオフライン音声 |
より高品質なローカルプロジェクト |
最高品質、豊富な音声オプション |