Nota
Hola, ¡bienvenido a la comunidad de entusiastas de SunFounder Raspberry Pi & Arduino & ESP32 en Facebook! Sumérgete aún más en el mundo de Raspberry Pi, Arduino y ESP32 con otros apasionados.
¿Por qué unirse?
Soporte de Expertos: Resuelve problemas post-venta y desafíos técnicos con la ayuda de nuestra comunidad y equipo.
Aprende y Comparte: Intercambia consejos y tutoriales para mejorar tus habilidades.
Avances Exclusivos: Obtén acceso anticipado a los anuncios de nuevos productos y a vistas previas.
Descuentos Especiales: Disfruta de descuentos exclusivos en nuestros productos más recientes.
Promociones y Sorteos Festivos: Participa en sorteos y promociones especiales durante las festividades.
👉 ¿Listo para explorar y crear con nosotros? Haz clic en [here] y únete hoy mismo.
17. Conversación de Texto con Ollama
En esta lección, aprenderás a usar Ollama, una herramienta para ejecutar modelos grandes de lenguaje y visión de forma local. Te mostraremos cómo instalar Ollama, descargar un modelo y conectar Pidog a él.
Antes de Comenzar
Asegúrate de haber completado:
Instalar Todos los Módulos (Importante) — Instalar los módulos
robot-hat,vilib,Pidogy luego ejecutar el scripti2samp.sh.
1. Instalar Ollama (LLM) y Descargar Modelo
Puedes elegir dónde instalar Ollama:
En tu Raspberry Pi (ejecución local)
O en otra computadora (Mac/Windows/Linux) en la misma red local
Modelos recomendados según el hardware
Puedes elegir cualquier modelo disponible en Ollama Hub. Los modelos vienen en diferentes tamaños (3B, 7B, 13B, 70B…). Los modelos más pequeños se ejecutan más rápido y requieren menos memoria, mientras que los más grandes ofrecen mejor calidad pero necesitan hardware más potente.
Consulta la siguiente tabla para decidir qué tamaño de modelo se adapta mejor a tu dispositivo.
Tamaño del modelo |
RAM mínima requerida |
Hardware recomendado |
|---|---|---|
~3B parámetros |
8GB (mejor con 16GB) |
Raspberry Pi 5 (16GB) o PC/Mac de gama media |
~7B parámetros |
16GB+ |
Pi 5 (16GB, apenas usable) o PC/Mac de gama media |
~13B parámetros |
32GB+ |
PC de escritorio / Mac con alta RAM |
30B+ parámetros |
64GB+ |
Estación de trabajo / Servidor / GPU recomendada |
70B+ parámetros |
128GB+ |
Servidor de gama alta con múltiples GPU |
Instalar en Raspberry Pi
Si deseas ejecutar Ollama directamente en tu Raspberry Pi:
Usa un Raspberry Pi OS de 64 bits
Muy recomendado: Raspberry Pi 5 (16GB RAM)
Ejecuta los siguientes comandos:
# Instalar Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Descargar un modelo liviano (bueno para pruebas)
ollama pull llama3.2:3b
# Prueba rápida (escribe 'hi' y presiona Enter)
ollama run llama3.2:3b
# Servir la API (puerto por defecto 11434)
# Consejo: establece OLLAMA_HOST=0.0.0.0 para permitir acceso desde la LAN
OLLAMA_HOST=0.0.0.0 ollama serve
Instalar en Mac / Windows / Linux (Aplicación de Escritorio)
Descarga e instala Ollama desde Ollama Download Page
Abre la aplicación Ollama, ve a Model Selector y usa la barra de búsqueda para encontrar un modelo. Por ejemplo, escribe
llama3.2:3b(un modelo pequeño y ligero para comenzar).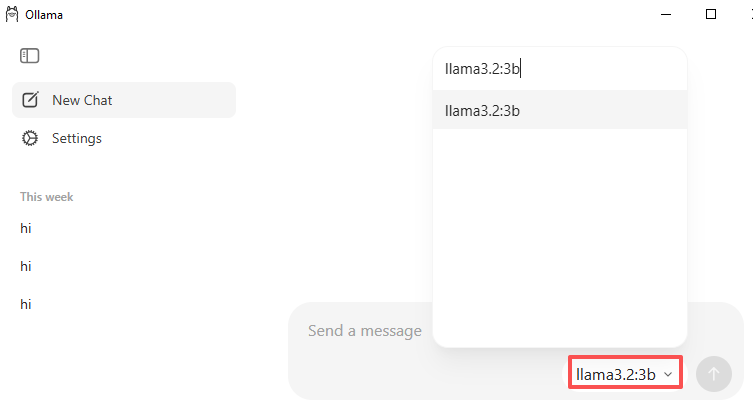
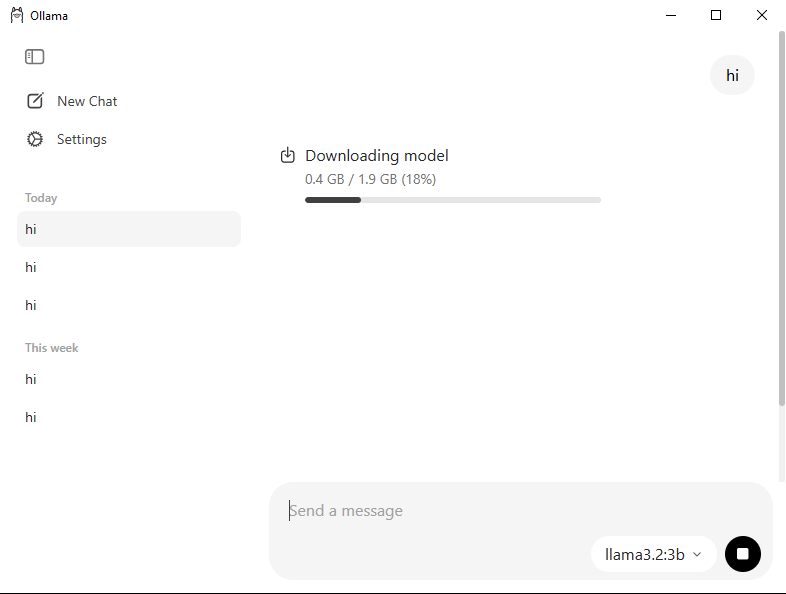
Una vez completada la descarga, escribe algo simple como “Hi” en la ventana de chat. Ollama iniciará la descarga automáticamente la primera vez que lo uses.
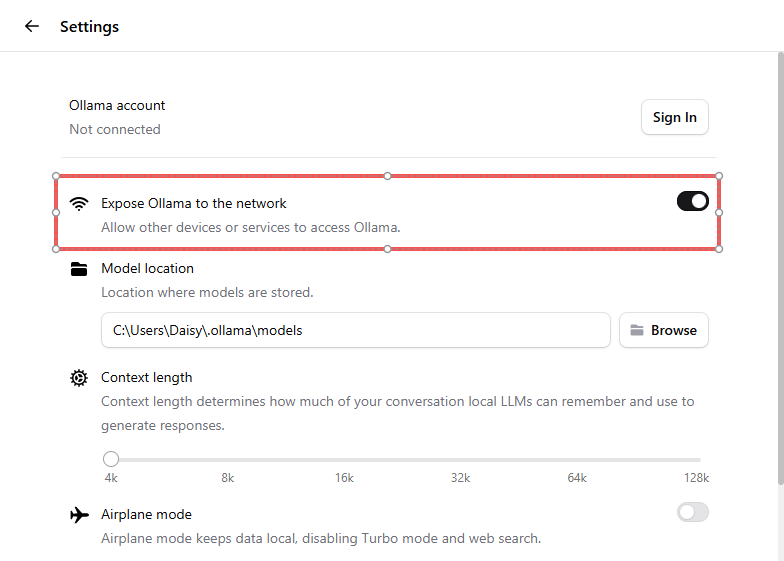
Ve a Settings → activa Expose Ollama to the network. Esto permite que tu Raspberry Pi se conecte a través de la red local (LAN).
Advertencia
Si ves un error como:
Error: model requires more system memory ...
El modelo es demasiado grande para tu máquina. Usa un modelo más pequeño o cambia a una computadora con más RAM.
2. Probar Ollama
Una vez que Ollama esté instalado y tu modelo esté listo, puedes probarlo rápidamente con un bucle de chat mínimo.
Pasos
Crea un nuevo archivo:
cd ~/pidog/examples nano test_llm_ollama.py
Pega el siguiente código y guarda (
Ctrl+X→Y→Enter):from pidog.llm import Ollama INSTRUCTIONS = "You are a helpful assistant." WELCOME = "Hello, I am a helpful assistant. How can I help you?" # If Ollama runs on the same Raspberry Pi, use "localhost". # If it runs on another computer in your LAN, replace with that computer's IP address. llm = Ollama( ip="localhost", model="llama3.2:3b" # you can replace with any model ) # Basic configuration llm.set_max_messages(20) llm.set_instructions(INSTRUCTIONS) llm.set_welcome(WELCOME) print(WELCOME) while True: text = input(">>> ") if text.strip().lower() in {"exit", "quit"}: break # Response with streaming output response = llm.prompt(text, stream=True) for token in response: if token: print(token, end="", flush=True) print("")
Ejecuta el programa:
python3 test_llm_ollama.pyAhora puedes chatear con Pidog directamente desde la terminal.
Puedes elegir cualquier modelo disponible en Ollama Hub, pero se recomiendan modelos más pequeños (por ejemplo,
moondream:1.8b,phi3:mini) si solo tienes 8–16GB de RAM.Asegúrate de que el modelo que especifiques en el código coincida con el que ya descargaste en Ollama.
Escribe
exitoquitpara detener el programa.Si no puedes conectarte, asegúrate de que Ollama esté en ejecución y que ambos dispositivos estén en la misma LAN si usas un host remoto.
Solución de Problemas
Recibo un error como: `model requires more system memory …`.
Esto significa que el modelo es demasiado grande para tu dispositivo.
Usa un modelo más pequeño como
moondream:1.8bogranite3.2-vision:2b.O cambia a una máquina con más RAM y expón Ollama a la red.
El código no puede conectarse a Ollama (conexión rechazada).
Verifica lo siguiente:
Asegúrate de que Ollama esté ejecutándose (
ollama serveo que la aplicación de escritorio esté abierta).Si usas una computadora remota, activa Expose to network en la configuración de Ollama.
Verifica que la dirección
ip="..."en tu código coincida con la IP correcta de la LAN.Confirma que ambos dispositivos estén en la misma red local.