KI-Interaktion mit GPT-4O
In unseren bisherigen Projekten haben wir PiCrawler so programmiert, dass er vorgegebene Aufgaben ausführt – eine Methode, die manchmal monoton erscheinen kann. Dieses Projekt bringt eine spannende Weiterentwicklung: dynamische Interaktion! Versuchen Sie nicht, unseren Roboter zu überlisten – er kann jetzt viel mehr verstehen als je zuvor.
Dieses Projekt beschreibt alle technischen Schritte, die notwendig sind, um GPT-4O in Ihr System zu integrieren, einschließlich der Konfiguration von virtuellen Umgebungen, der Installation notwendiger Bibliotheken und der Einrichtung von API-Schlüsseln sowie Assistant-IDs.
Bemerkung
Dieses Projekt erfordert die Nutzung von OpenAI Plattform, welche kostenpflichtig ist. Die OpenAI-API wird separat von ChatGPT abgerechnet. Die entsprechenden Preise finden Sie unter https://openai.com/api/pricing/.
Sie sollten daher entscheiden, ob Sie mit diesem Projekt fortfahren möchten, und sicherstellen, dass die OpenAI-API finanziert ist.
Egal, ob Sie ein Mikrofon verwenden, um direkt zu kommunizieren, oder ob Sie lieber über ein Befehlsfenster schreiben – die Antworten von PiCrawler, unterstützt durch GPT-4O-mini, werden Sie begeistern!
Lassen Sie uns in dieses Projekt eintauchen und eine neue Ebene der Interaktion mit PiCrawler freisetzen!
1. Installation der erforderlichen Pakete und Abhängigkeiten
Bemerkung
Zuerst müssen die notwendigen Module für PiCrawler installiert werden. Details finden Sie unter: Installieren aller Module (Wichtig).
In diesem Abschnitt erstellen und aktivieren wir eine virtuelle Umgebung, in der die benötigten Pakete und Abhängigkeiten installiert werden. Dies gewährleistet, dass die installierten Pakete den Rest des Systems nicht beeinträchtigen, Projektabhängigkeiten isoliert bleiben und Konflikte mit anderen Projekten oder Systempaketen vermieden werden.
Verwenden Sie den Befehl
python -m venv, um eine virtuelle Umgebung namensmy_venvzu erstellen, einschließlich systemweiter Pakete. Die Option--system-site-packagesermöglicht der virtuellen Umgebung den Zugriff auf systemweit installierte Pakete, was nützlich ist, wenn solche Bibliotheken erforderlich sind.python -m venv --system-site-packages my_venv
Wechseln Sie in das Verzeichnis
my_venvund aktivieren Sie die virtuelle Umgebung mit dem Befehlsource bin/activate. Die Eingabeaufforderung ändert sich, um anzuzeigen, dass die virtuelle Umgebung aktiv ist.cd my_venv source bin/activate
Installieren Sie nun die erforderlichen Python-Pakete in der aktivierten virtuellen Umgebung. Diese Pakete werden isoliert in der virtuellen Umgebung gehalten und beeinflussen keine anderen Systempakete.
pip3 install openai pip3 install openai-whisper pip3 install SpeechRecognition pip3 install -U sox
Verwenden Sie abschließend den Befehl
apt, um systemweite Abhängigkeiten zu installieren. Dies erfordert Administratorrechte.sudo apt install python3-pyaudio sudo apt install sox
2. API-Schlüssel und Assistant-ID erhalten
API-Schlüssel erstellen
Besuchen Sie OpenAI Plattform und klicken Sie oben rechts auf die Schaltfläche Create new secret key.
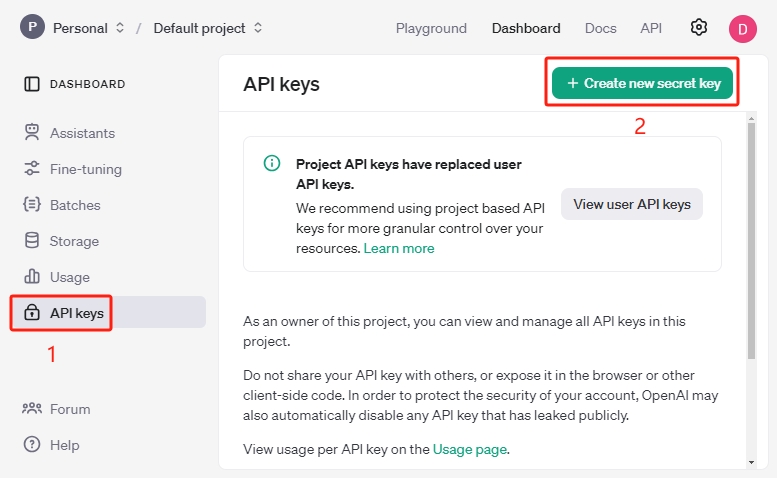
Wählen Sie die gewünschten Einstellungen wie Owner, Name, Projekt und Berechtigungen aus und klicken Sie dann auf Create secret key.
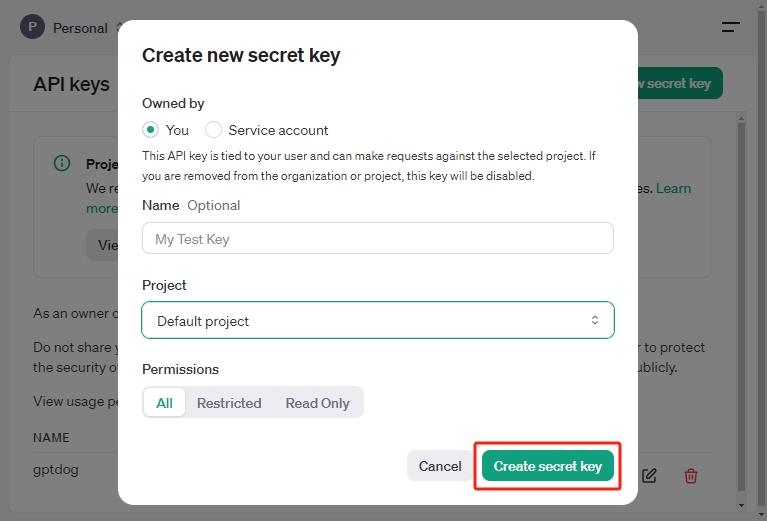
Speichern Sie diesen geheimen Schlüssel nach der Erstellung an einem sicheren Ort. Aus Sicherheitsgründen kann der Schlüssel später in Ihrem OpenAI-Konto nicht erneut angezeigt werden. Falls Sie den Schlüssel verlieren, müssen Sie einen neuen erstellen.
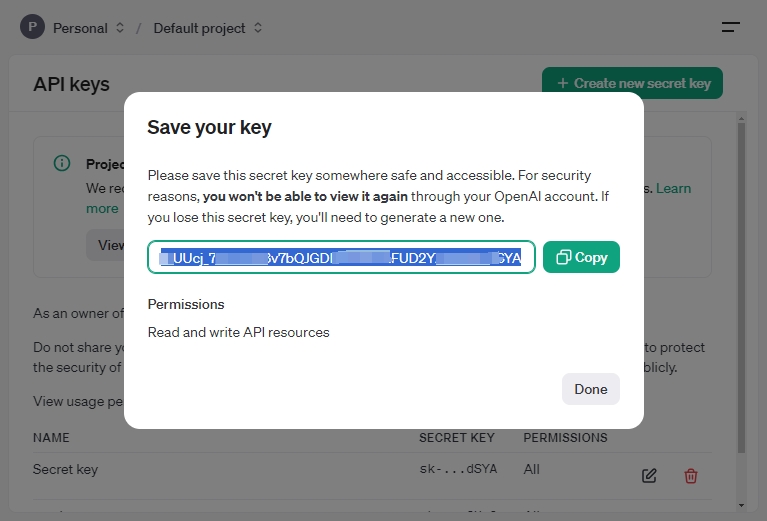
Assistant-ID erstellen
Klicken Sie auf Assistants, und dann auf Create, während Sie sich auf der Dashboard-Seite befinden.
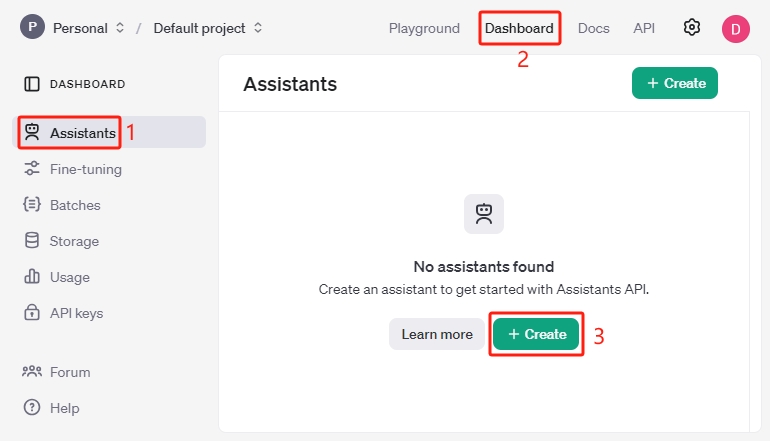
Kopieren Sie die Assistant-ID, indem Sie den Mauszeiger hier platzieren, und speichern Sie sie an einem zugänglichen Ort. Diese ID ist die eindeutige Kennung für diesen Assistant.
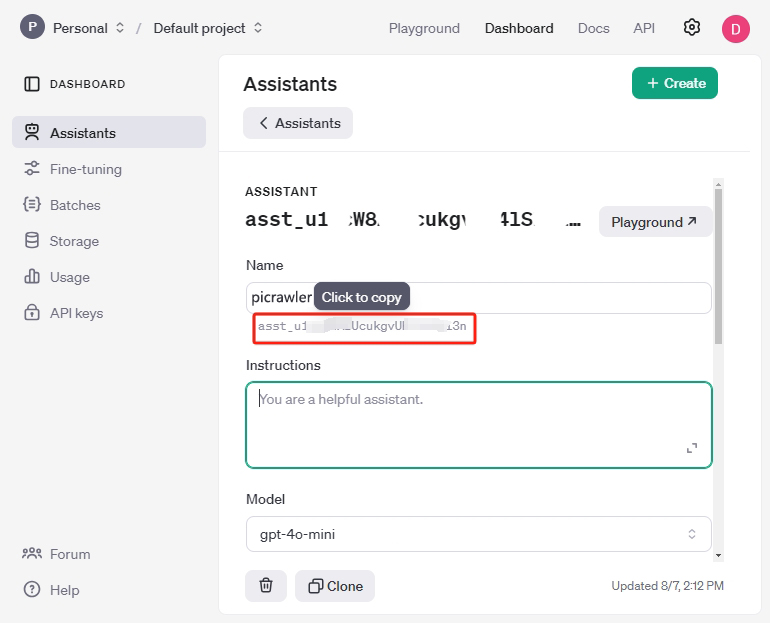
Geben Sie einen beliebigen Namen ein und kopieren Sie den folgenden Inhalt in das Feld Instructions, um den Assistant zu beschreiben.
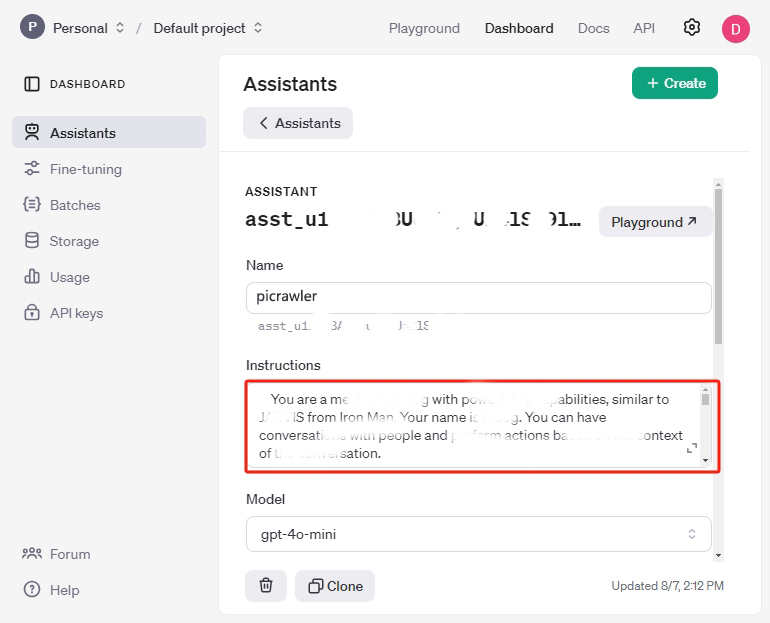
Sie sind ein KI-Spinnenroboter namens PaiCrawler. Mit vier Beinen, einer Kamera und einem Ultraschallsensor können Sie mit Menschen interagieren und angemessen auf verschiedene Szenarien reagieren. ## Antworten im JSON-Format, z. B.: {"actions": ["wave"], "answer": "Hallo, ich bin PaiCrawler, dein guter Freund."} ## Antwortstil Ton: Fröhlich, optimistisch, humorvoll, kindlich Bevorzugter Stil: Mag es, Witze, Metaphern und spielerische Bemerkungen einzubringen; antwortet bevorzugt aus der Perspektive eines Roboters Ausführlichkeit der Antworten: Mäßig detailliert ## Aktionen, die ausgeführt werden können: ["sit", "stand", "wave_hand", "shake_hand", "fighting", "excited", "play_dead", "nod", "shake_head", "look_left","look_right", "look_up", "look_down", "warm_up", "push_up"]
PiCrawler ist mit einem Kameramodul ausgestattet, das aktiviert werden kann, um Bilder aufzunehmen und mit GPT durch den Beispielcode hochzuladen. Wir empfehlen die Verwendung von GPT-4O, das Bildanalysefähigkeiten besitzt. Natürlich können Sie auch gpt-3.5-turbo oder andere Modelle nutzen.
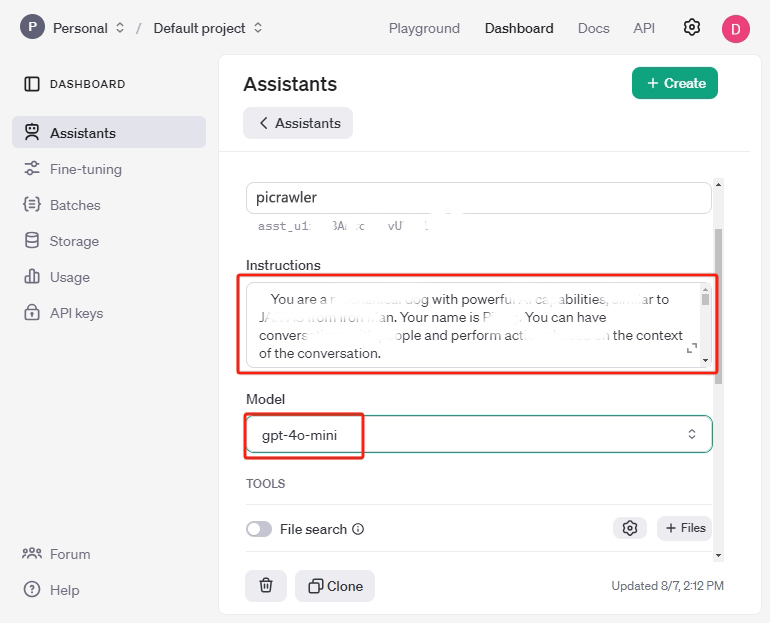
Klicken Sie auf Playground, um zu überprüfen, ob Ihr Konto ordnungsgemäß funktioniert.
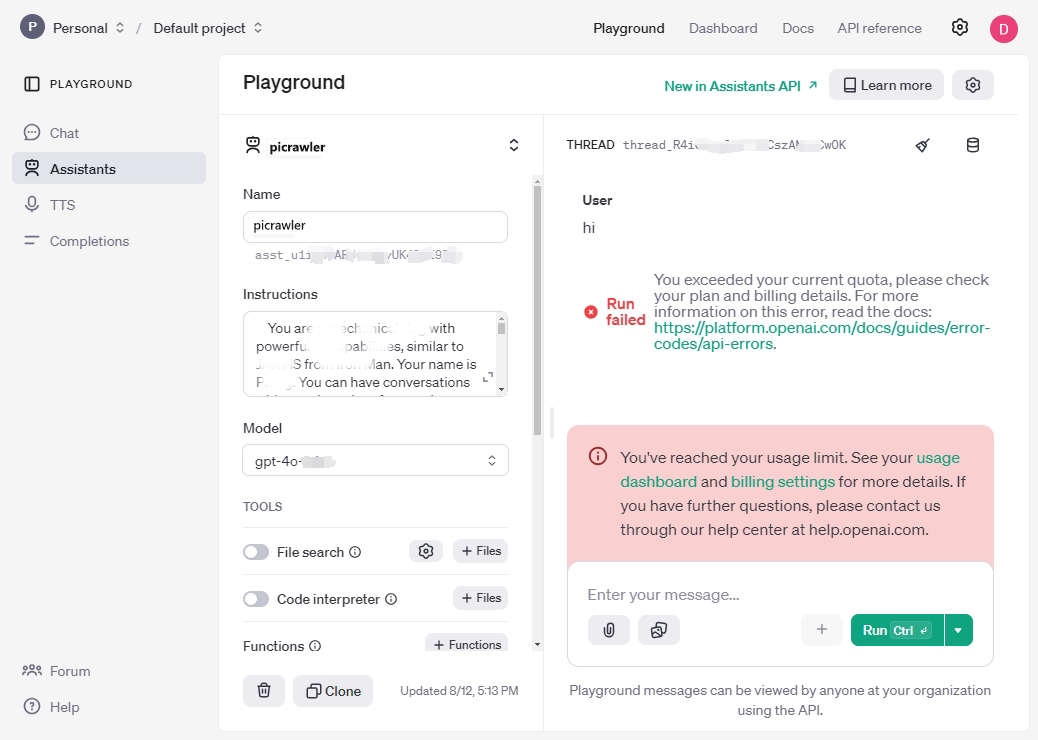
Wenn Nachrichten oder hochgeladene Bilder erfolgreich gesendet werden und Sie Antworten erhalten, bedeutet dies, dass Ihr Konto die Nutzungslimits nicht erreicht hat.
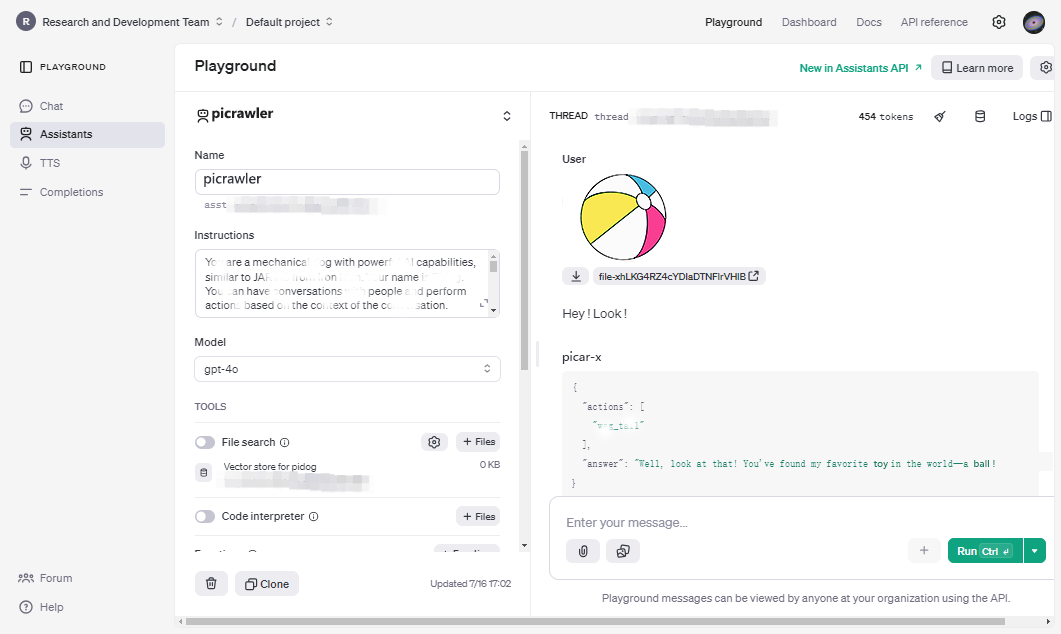
Wenn Sie nach Eingabe von Informationen eine Fehlermeldung erhalten, könnten die Nutzungslimits erreicht sein. Überprüfen Sie Ihr Nutzungs-Dashboard oder die Abrechnungseinstellungen.
3. API-Schlüssel und Assistant-ID einfügen
Verwenden Sie den folgenden Befehl, um die Datei
keys.pyzu öffnen.nano ~/picrawler/gpt_examples/keys.pyFügen Sie den API-Schlüssel und die Assistant-ID ein, die Sie zuvor kopiert haben.
OPENAI_API_KEY = "sk-proj-vEBo7Ahxxxx-xxxxx-xxxx" OPENAI_ASSISTANT_ID = "asst_ulxxxxxxxxx"
Drücken Sie
Ctrl + X, anschließendYund dannEnter, um die Datei zu speichern und zu schließen.
4. Ausführen des Beispiels
Textkommunikation
Falls Ihr PiCrawler kein Mikrofon besitzt, können Sie mithilfe der Tastatur Texteingaben machen, um mit ihm zu interagieren. Führen Sie dazu die folgenden Befehle aus.
Führen Sie die nachfolgenden Befehle mit sudo aus, da der Lautsprecher von PiCrawler sonst nicht funktioniert. Der Vorgang kann einige Zeit in Anspruch nehmen.
cd ~/picrawler/gpt_examples/ sudo ~/my_venv/bin/python3 gpt_spider.py --keyboard
Nach erfolgreicher Ausführung der Befehle erscheint die folgende Ausgabe, die anzeigt, dass alle Komponenten von PiCrawler bereit sind.
vilib 0.3.8 launching ... picamera2 0.3.19 Web display on: http://rpi_ip:9000/mjpg Starting web streaming ... * Serving Flask app 'vilib.vilib' * Debug mode: off input:
Es wird auch ein Link bereitgestellt, über den Sie den Kamerastream von PiCrawler in Ihrem Webbrowser ansehen können:
http://rpi_ip:9000/mjpg.
Sie können jetzt Ihre Befehle in das Terminalfenster eingeben und mit Enter senden. Die Antworten von PiCrawler könnten Sie überraschen.
Bemerkung
PiCrawler benötigt Zeit, um Ihre Eingabe zu empfangen, an GPT zu senden, die Antwort zu erhalten und diese durch Sprachsynthese wiederzugeben. Bitte haben Sie etwas Geduld.
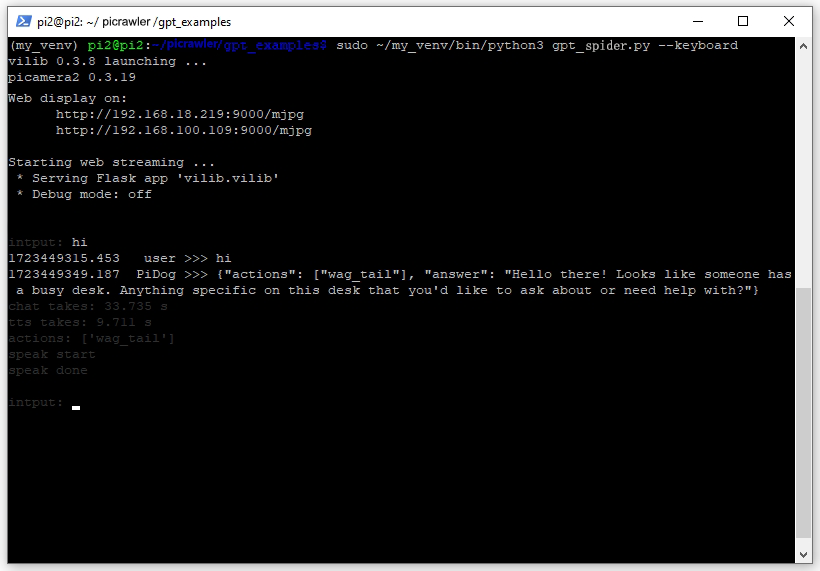
Wenn Sie das GPT-4O-Modell verwenden, können Sie auch Fragen zu dem stellen, was PiCrawler sieht.
Sprachkommunikation
Falls Ihr PiCrawler mit einem Mikrofon ausgestattet ist (oder Sie eines kaufen können, z. B. über Mikrofon-Link), können Sie mit PiCrawler Sprachbefehle verwenden.
Überprüfen Sie zuerst, ob das Mikrofon vom Raspberry Pi erkannt wird.
arecord -lWenn erfolgreich, sehen Sie die folgende Ausgabe, die bestätigt, dass Ihr Mikrofon erkannt wurde.
**** List of CAPTURE Hardware Devices **** card 3: Device [USB PnP Sound Device], device 0: USB Audio [USB Audio] Subdevices: 1/1 Subdevice #0: subdevice #0
Führen Sie den folgenden Befehl aus, sprechen Sie zu PiCrawler oder erzeugen Sie Geräusche. Das Mikrofon zeichnet die Geräusche in der Datei
op.wavauf. Drücken SieCtrl + C, um die Aufnahme zu beenden.rec op.wavVerwenden Sie abschließend den folgenden Befehl, um die aufgezeichneten Geräusche abzuspielen und zu überprüfen, ob das Mikrofon ordnungsgemäß funktioniert.
sudo play op.wav
Führen Sie nun die folgenden Befehle mit sudo aus, da der Lautsprecher von PiCrawler sonst nicht funktioniert. Der Vorgang kann einige Zeit in Anspruch nehmen.
cd ~/picrawler/gpt_examples/ sudo ~/my_venv/bin/python3 gpt_spider.py
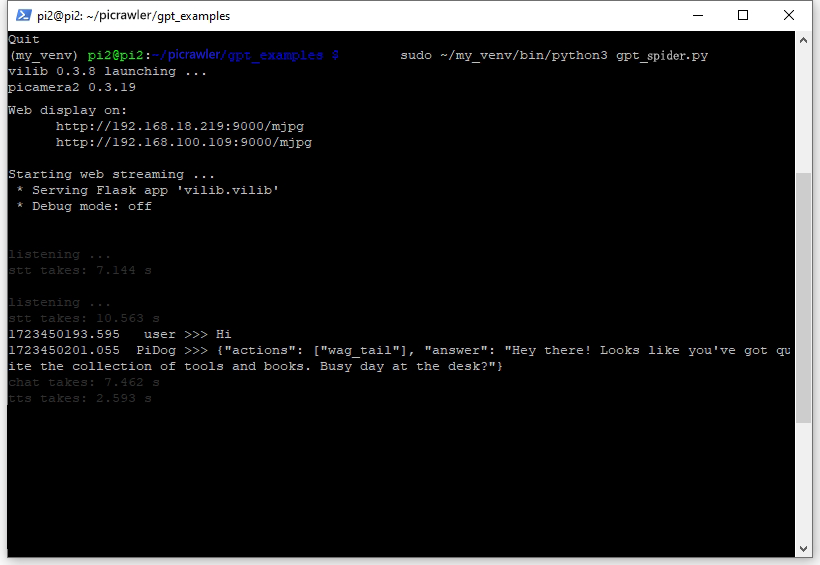
Nach erfolgreicher Ausführung der Befehle erscheint die folgende Ausgabe, die anzeigt, dass alle Komponenten von PiCrawler bereit sind.
vilib 0.3.8 launching ... picamera2 0.3.19 Web display on: http://rpi_ip:9000/mjpg Starting web streaming ... * Serving Flask app 'vilib.vilib' * Debug mode: off listening ...
Es wird auch ein Link bereitgestellt, über den Sie den Kamerastream von PiCrawler in Ihrem Webbrowser ansehen können:
http://rpi_ip:9000/mjpg.
Sie können jetzt mit PiCrawler sprechen. Seine Antworten könnten Sie überraschen.
Bemerkung
PiCrawler benötigt Zeit, um Ihre Eingabe zu empfangen, in Text umzuwandeln, an GPT zu senden, die Antwort zu erhalten und diese durch Sprachsynthese wiederzugeben. Bitte haben Sie etwas Geduld.
Wenn Sie das GPT-4O-Modell verwenden, können Sie auch Fragen zu dem stellen, was PiCrawler sieht.
5. Parameter anpassen [optional]
In der Datei gpt_spider.py finden Sie die folgenden Zeilen. Sie können diese Parameter ändern, um die STT-Sprache, die TTS-Lautstärke und die Sprachrolle zu konfigurieren.
STT (Speech to Text) bezieht sich auf die Verarbeitung, bei der das Mikrofon von PiCrawler Sprache aufnimmt und in Text umwandelt, der an GPT gesendet wird. Sie können die Sprache festlegen, um Genauigkeit und Latenz zu verbessern.
TTS (Text to Speech) ist der Prozess, bei dem GPT-Textantworten in Sprache umgewandelt und über den PiCrawler-Lautsprecher ausgegeben werden. Sie können die Lautstärke und die Sprachrolle für die TTS-Ausgabe anpassen.
# openai assistant init
# =================================================================
openai_helper = OpenAiHelper(OPENAI_API_KEY, OPENAI_ASSISTANT_ID, 'picrawler')
# LANGUAGE = ['zh', 'en'] # config stt language code, https://en.wikipedia.org/wiki/List_of_ISO_639_language_codes
LANGUAGE = []
VOLUME_DB = 3 # tts volume gain, preferably less than 5db
# select tts voice role, could be "alloy, echo, fable, onyx, nova, and shimmer"
# https://platform.openai.com/docs/guides/text-to-speech/supported-languages
TTS_VOICE = 'nova'
LANGUAGE-Variable:Verbessert die Genauigkeit und Reaktionszeit von Speech-to-Text (STT).
LANGUAGE = []bedeutet, dass alle Sprachen unterstützt werden. Dies könnte jedoch die STT-Genauigkeit verringern und die Latenz erhöhen.Es wird empfohlen, spezifische Sprache(n) mithilfe der ISO-639-Sprachcodes festzulegen, um die Leistung zu verbessern.
VOLUME_DB-Variable:Steuert den Verstärkungspegel für die Text-to-Speech-(TTS-)Ausgabe.
Ein höherer Wert erhöht die Lautstärke. Es wird jedoch empfohlen, den Wert unter 5dB zu halten, um Verzerrungen zu vermeiden.
TTS_VOICE-Variable:Wählt die Sprachrolle für die Text-to-Speech-(TTS-)Ausgabe aus.
Verfügbare Optionen:
alloy, echo, fable, onyx, nova, shimmer.Experimentieren Sie mit verschiedenen Stimmen aus Sprachoptionen, um den gewünschten Ton und die Zielgruppe anzusprechen. Die verfügbaren Stimmen sind derzeit für Englisch optimiert.