Bemerkung
Hallo, willkommen in der SunFounder Raspberry Pi & Arduino & ESP32 Enthusiasten-Community auf Facebook! Tauchen Sie mit anderen Enthusiasten tiefer in Raspberry Pi, Arduino und ESP32 ein.
Warum beitreten?
Expertenunterstützung: Lösen Sie Probleme nach dem Kauf und technische Herausforderungen mit Hilfe unserer Community und unseres Teams.
Lernen & Teilen: Tauschen Sie Tipps und Tutorials aus, um Ihre Fähigkeiten zu verbessern.
Exklusive Vorschauen: Erhalten Sie frühzeitigen Zugang zu neuen Produktankündigungen und Sneak Peeks.
Sonderrabatte: Genießen Sie exklusive Rabatte auf unsere neuesten Produkte.
Festliche Aktionen und Gewinnspiele: Nehmen Sie an Gewinnspielen und Feiertagsaktionen teil.
👉 Bereit, mit uns zu entdecken und zu gestalten? Klicken Sie auf [here] und treten Sie noch heute bei!
2. Alles erkennen mit YOLOE
YOLOE (You Only Look Once with Embeddings) ist das neueste Mitglied der YOLO-Familie und führt gemeinsame Sprach-Bild-Lernfähigkeiten in das traditionelle YOLO ein. Einfach ausgedrückt kann YOLOE nicht nur Objekte erkennen, auf denen es trainiert wurde, sondern auch beliebige neue Objekte durch Textbeschreibungen oder Eingabeaufforderungen (Prompts) ohne erneutes Training erkennen.
Hauptmerkmale von YOLOE:
Offene Vokabulareerkennung: Erkennung beliebiger Objekte durch Textbeschreibungen, nicht beschränkt auf vordefinierte Kategorien
Prompt-Freier Modus: Automatische Erkennung markanter Objekte in Bildern ohne jegliche Eingabeaufforderungen
Effiziente Bereitstellung: Erbt die effiziente Architektur von YOLO und läuft reibungslos auf dem Raspberry Pi
Multitasking-Unterstützung: Unterstützt verschiedene Aufgaben, einschließlich Objekterkennung und Instanzsegmentierung
Dies macht YOLOE besonders geeignet für schnelle Prototypenerstellung und Anwendungen, die eine flexible Erkennung verschiedener Objekte erfordern.
Installieren von Abhängigkeiten
Installieren Sie zuerst die für YOLOE erforderliche CLIP-Bibliothek:
pip3 install git+https://github.com/ultralytics/CLIP.git --break-system-packages
Prompt-Freier Modus
Der prompt-freie Modus ist die intuitivste Art, YOLOE zu verwenden. In diesem Modus erkennt das Modell automatisch alle markanten Objekte im Bild ohne jegliche Textvorgaben. Dies verhält sich ähnlich wie traditionelles YOLO, jedoch mit besseren Fähigkeiten für offene Vokabulare.
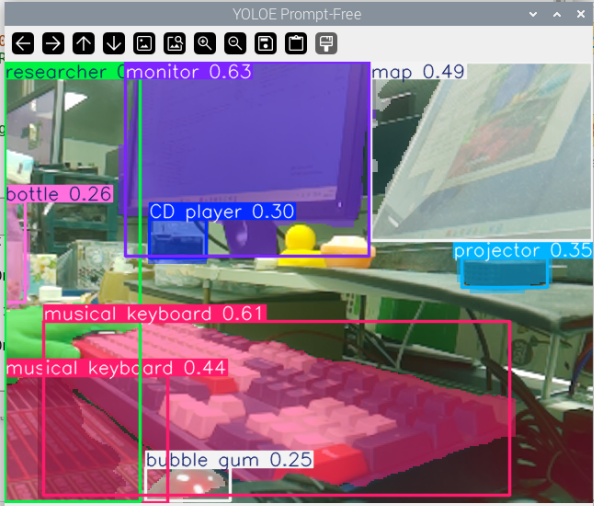
Abbildung: Ich richtete die Kamera auf meinen überfüllten Schreibtisch, und der prompt-freie Modus von YOLOE identifizierte und segmentierte automatisch alle markanten Objekte im Blickfeld – Monitor, Tastatur, Wassertasse, Notizbuch, Maus … Jedes Objekt wird mit einer andersfarbigen Segmentierungsmaske annotiert, ohne dass Textvorgaben erforderlich sind. Alles wird auf einen Blick klar dargestellt.
Funktionsweise: Das Modell identifiziert automatisch Vordergrundobjekte im Bild durch visuelle Merkmalsanalyse und führt eine Segmentierung durch. Dieser Ansatz eignet sich zum schnellen Durchsuchen von Bildinhalten oder wenn Sie sich nicht sicher sind, welche Objekte erkannt werden müssen.
Der folgende Code zeigt, wie YOLOE im prompt-freien Modus auf einem Raspberry Pi ausgeführt wird:
cd ~/ai-lab-kit/yolo
python3 yoloe_prompt_free.py
from ultralytics import YOLO
from picamera2 import Picamera2
import cv2
# Prompt-freier Modus
model = YOLO("yoloe-11s-seg-pf.pt") # pf = prompt-free
picam2 = Picamera2()
picam2.preview_configuration.main.size = (640, 480)
picam2.preview_configuration.main.format = "RGB888"
picam2.configure("preview")
picam2.start()
print("Prompt-freier Modus: Erkenne automatisch alles...")
print("Drücken Sie 'q' zum Beenden")
while True:
frame = picam2.capture_array()
results = model.predict(frame, imgsz=320)
annotated = results[0].plot()
cv2.imshow("YOLOE Prompt-Frei", annotated)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
picam2.stop()
Merkmale des prompt-freien Modus:
Keine Konfiguration nötig: Direkt ausführbar zur Erkennung markanter Objekte in Bildern
Automatische Segmentierung: Ausgabe sowohl von Erkennungsrahmen als auch von Segmentierungsmasken
Keine Klassenbezeichnungen: Zeigt nur erkannte Objektpositionen ohne Kategorienamen an
Anwendungsfälle: Schnelles Durchsuchen, allgemeine Objekterkennung, Entdecken unbekannter Objekte
Text-Prompt-Modus
Der Text-Prompt-Modus ist der Bereich, in dem die Leistungsfähigkeit von YOLOE wirklich zur Geltung kommt. Durch natürlichsprachliche Beschreibungen können Sie dem Modell mitteilen, welche Objekte es erkennen soll, und das Modell identifiziert und lokalisiert diese Objekte in Echtzeit.
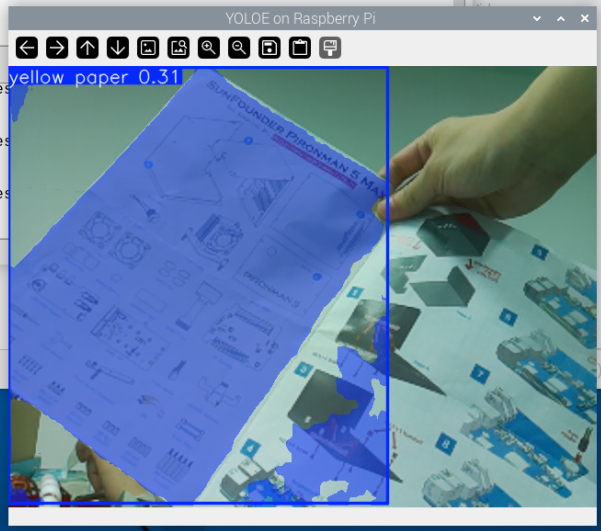
Abbildung: Ich hielt ein Blatt Papier, das zur Hälfte gelb und zur Hälfte weiß war, vor die Kamera und verwendete einen Text-Prompt, um dem Modell mitzuteilen, es solle nach „gelbem Papier“ suchen. YOLOE verstand diese Beschreibung genau, segmentierte nur die gelbe Hälfte des Papiers und markierte sie mit einem Begrenzungsrahmen, während es den weißen Teil völlig ignorierte. Dies demonstriert die Fähigkeit von YOLOE, eine feinkörnige Objekterkennung durch natürliche Sprache durchzuführen.
Funktionsweise: Das Modell kodiert Text-Prompts in Merkmalsvektoren und gleicht sie dann mit Bildmerkmalen ab, um Regionen zu identifizieren, die am besten zu den Textbeschreibungen passen. Dieser Ansatz ermöglicht es Ihnen, Erkennungsziele dynamisch festzulegen, ohne das Modell neu zu trainieren.
Der folgende Code zeigt, wie Sie Text-Prompts verwenden, um bestimmte Objekte zu erkennen:
cd ~/ai-lab-kit/yolo
python3 yoloe_prompt_text.py
from ultralytics import YOLOE
from picamera2 import Picamera2
import cv2
# YOLOE-Modell laden
model = YOLOE("yoloe-26n-seg.pt") # Nano-Version
# die zu erkennenden Klassen festlegen (Text-Prompt)
names = ["gelbes Papier", "rote Tasse", "Person mit Brille"]
model.set_classes(names, model.get_text_pe(names))
# Kamera initialisieren
picam2 = Picamera2()
picam2.preview_configuration.main.size = (640, 480)
picam2.preview_configuration.main.format = "RGB888"
picam2.configure("preview")
picam2.start()
print("YOLOE läuft mit Text-Prompts, drücken Sie 'q' zum Beenden...")
print(f"Erkennung: {', '.join(names)}")
while True:
frame = picam2.capture_array()
results = model.predict(frame, conf=0.3) # Konfidenzschwelle auf 0,3 setzen
annotated = results[0].plot()
cv2.imshow("YOLOE auf dem Raspberry Pi", annotated)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
picam2.stop()
Merkmale des Text-Prompt-Modus:
Dynamische Erkennung: Erkennungsziele jederzeit ohne erneutes Training ändern
Natürliche Sprache: Verwenden Sie Alltagssprache zur Beschreibung von Objekten, wie „blaues Auto“, „hölzerner Stuhl“
Multi-Ziel-Erkennung: Mehrere Erkennungsziele gleichzeitig angeben
Feinkörnige Steuerung: Beschreiben Sie Attribute wie Farbe, Material, Form usw.
Konfidenzschwelle: Steuern Sie die Erkennungsempfindlichkeit über den Parameter
conf
Fortgeschrittene Anwendung
Dynamisches Umschalten von Erkennungszielen
Sie können Text-Prompts zur Laufzeit ändern, ohne das Programm neu starten zu müssen:
# Modell initialisieren
model = YOLOE("yoloe-26n-seg.pt")
# Anfängliche Erkennungsziele
current_names = ["roter Apfel"]
model.set_classes(current_names, model.get_text_pe(current_names))
while True:
frame = picam2.capture_array()
# Prüfen, ob das Erkennungsziel gewechselt werden soll
key = cv2.waitKey(1) & 0xFF
if key == ord('1'):
current_names = ["Banane"]
model.set_classes(current_names, model.get_text_pe(current_names))
print("Erkenne jetzt: Banane")
elif key == ord('2'):
current_names = ["Orange"]
model.set_classes(current_names, model.get_text_pe(current_names))
print("Erkenne jetzt: Orange")
results = model.predict(frame, conf=0.3)
annotated = results[0].plot()
cv2.imshow("YOLOE", annotated)
if key == ord('q'):
break
Verwendung komplexerer Textbeschreibungen
YOLOE unterstützt komplexe natürlichsprachliche Beschreibungen für eine präzisere Objektlokalisierung:
# Beispiele für präzisere Beschreibungen
names = [
"Person mit rotem Hut",
"Auto mit offener Tür",
"kleiner Hund auf der linken Seite",
"gelbes Papier auf dem Schreibtisch"
]
model.set_classes(names, model.get_text_pe(names))
Anpassen der Erkennungsparameter
Leistungsoptimierung für den Raspberry Pi:
# Leistungsoptimierungskonfiguration
results = model.predict(
frame,
imgsz=224, # Niedrigere Auflösung für höhere Geschwindigkeit
conf=0.4, # Höhere Konfidenzschwelle reduziert Fehlerkennungen
iou=0.5, # IOU-Schwelle anpassen
verbose=False # Ausführliche Ausgabe deaktivieren
)
Tipps zur Leistungsoptimierung
Beim Ausführen von YOLOE auf dem Raspberry Pi können die folgenden Optimierungen zu einer besseren Leistung verhelfen:
Das richtige Modell wählen:
yoloe-26n-seg.pt: Nano-Version, schnellste Geschwindigkeityoloe-11s-seg-pf.pt: S-Version, höhere Genauigkeit, aber langsamer
Eingangsauflösung reduzieren:
imgsz=224: Höchste Geschwindigkeitimgsz=320: Ausgewogene Wahl (empfohlen)imgsz=416: Höhere Genauigkeit
Konfidenzschwelle anpassen:
Eine Erhöhung des
conf-Parameters (z. B. auf 0,5) reduziert die Anzahl der Erkennungen und verbessert die Geschwindigkeit
Erkennungskategorien reduzieren:
Im Text-Prompt-Modus kann die Begrenzung der Länge der
names-Liste die Inferenzgeschwindigkeit verbessern
FAQ
F: Was ist der Unterschied zwischen YOLOE und traditionellem YOLO?
A: Traditionelles YOLO kann nur feste Kategorien erkennen, die während des Trainings definiert wurden, während YOLOE beliebige Objekte durch Text-Prompts ohne erneutes Training erkennen kann.
F: Erkennt der prompt-freie Modus alle Objekte?
A: Der prompt-freie Modus erkennt visuell markante Objekte im Bild, liefert aber keine Kategorielabels, was ihn zum schnellen Durchsuchen von Szenen geeignet macht.
F: Unterstützt der Text-Prompt Chinesisch?
A: Für beste Ergebnisse werden englische Prompts empfohlen, da das Modell hauptsächlich mit englischen Daten trainiert wurde.
F: Wie hoch ist die Geschwindigkeit von YOLOE auf dem Raspberry Pi?
A: Auf dem Raspberry Pi 5 können Sie mit dem Nano-Modell und 320er Auflösung eine Echtzeitleistung von 3-5 FPS erreichen.
F: Kann ich mehrere Text-Prompts gleichzeitig verwenden?
A: Ja, fügen Sie einfach mehrere Beschreibungen zur names-Liste hinzu, und das Modell erkennt alle diese Objekte gleichzeitig.