Note
Hello, welcome to the SunFounder Raspberry Pi & Arduino & ESP32 Enthusiasts Community on Facebook! Dive deeper into Raspberry Pi, Arduino, and ESP32 with fellow enthusiasts.
Why Join?
Expert Support: Solve post-sale issues and technical challenges with help from our community and team.
Learn & Share: Exchange tips and tutorials to enhance your skills.
Exclusive Previews: Get early access to new product announcements and sneak peeks.
Special Discounts: Enjoy exclusive discounts on our newest products.
Festive Promotions and Giveaways: Take part in giveaways and holiday promotions.
👉 Ready to explore and create with us? Click [here] and join today!
17. Text Talk with Ollama
In this lesson, you will learn how to use Ollama, a tool for running large language and vision models locally. We will show you how to install Ollama, download a model, and connect Pidog to it.
Before You Start
Make sure you‘ve completed:
Install All the Modules(Important) — Install
robot-hat,vilib,Pidogmodules, then run the scripti2samp.sh.
1. Install Ollama (LLM) and Download Model
You can choose where to install Ollama:
On your Raspberry Pi (local run)
Or on another computer (Mac/Windows/Linux) in the same local network
Recommended models vs hardware
You can choose any model available on Ollama Hub. Models come in different sizes (3B, 7B, 13B, 70B…). Smaller models run faster and require less memory, while larger models provide better quality but need powerful hardware.
Check the table below to decide which model size fits your device.
Model size |
Min RAM Required |
Recommended Hardware |
|---|---|---|
~3B parameters |
8GB (16GB better) |
Raspberry Pi 5 (16GB) or mid-range PC/Mac |
~7B parameters |
16GB+ |
Pi 5 (16GB, just usable) or mid-range PC/Mac |
~13B parameters |
32GB+ |
Desktop PC / Mac with high RAM |
30B+ parameters |
64GB+ |
Workstation / Server / GPU recommended |
70B+ parameters |
128GB+ |
High-end server with multiple GPUs |
Install on Raspberry Pi
If you want to run Ollama directly on your Raspberry Pi:
Use a 64-bit Raspberry Pi OS
Strongly recommended: Raspberry Pi 5 (16GB RAM)
Run the following commands:
# Install Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Pull a lightweight model (good for testing)
ollama pull llama3.2:3b
# Quick run test (type 'hi' and press Enter)
ollama run llama3.2:3b
# Serve the API (default port 11434)
# Tip: set OLLAMA_HOST=0.0.0.0 to allow access from LAN
OLLAMA_HOST=0.0.0.0 ollama serve
Install on Mac / Windows / Linux (Desktop App)
Download and install Ollama from Ollama Download Page
Open the Ollama app, go to the Model Selector, and use the search bar to find a model. For example, type
llama3.2:3b(a small and lightweight model to start with).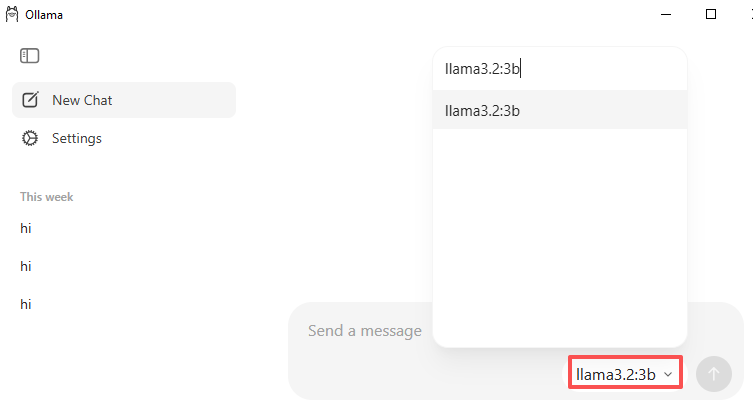
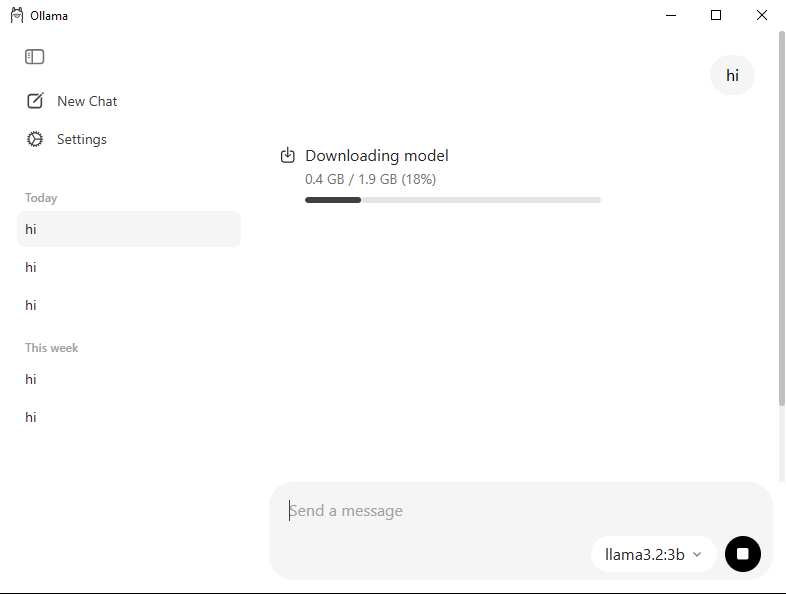
After the download is complete, type something simple like “Hi” in the chat window, Ollama will automatically start downloading it when you first use it.
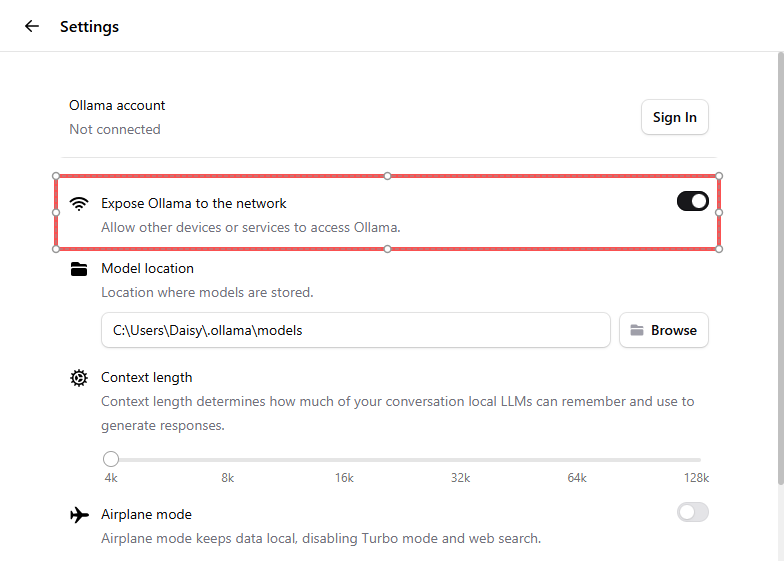
Go to Settings → enable Expose Ollama to the network. This allows your Raspberry Pi to connect to it over LAN.
Warning
If you see an error like:
Error: model requires more system memory ...
The model is too large for your machine. Use a smaller model or switch to a computer with more RAM.
2. Test Ollama
Once Ollama is installed and your model is ready, you can quickly test it with a minimal chat loop.
Steps
Create a new file:
cd ~/pidog/examples nano test_llm_ollama.py
Paste the following code and save (
Ctrl+X→Y→Enter):from pidog.llm import Ollama INSTRUCTIONS = "You are a helpful assistant." WELCOME = "Hello, I am a helpful assistant. How can I help you?" # If Ollama runs on the same Raspberry Pi, use "localhost". # If it runs on another computer in your LAN, replace with that computer's IP address. llm = Ollama( ip="localhost", model="llama3.2:3b" # you can replace with any model ) # Basic configuration llm.set_max_messages(20) llm.set_instructions(INSTRUCTIONS) llm.set_welcome(WELCOME) print(WELCOME) while True: text = input(">>> ") if text.strip().lower() in {"exit", "quit"}: break # Response with streaming output response = llm.prompt(text, stream=True) for token in response: if token: print(token, end="", flush=True) print("")
Run the program:
python3 test_llm_ollama.pyNow you can chat with Pidog directly from the terminal.
You can choose any model available on Ollama Hub, but smaller models (e.g.
moondream:1.8b,phi3:mini) are recommended if you only have 8–16GB RAM.Make sure the model you specify in the code matches the model you have already pulled in Ollama.
Type
exitorquitto stop the program.If you cannot connect, ensure that Ollama is running and that both devices are on the same LAN if you are using a remote host.
Troubleshooting
I get an error like: `model requires more system memory …`.
This means the model is too large for your device.
Use a smaller model such as
moondream:1.8borgranite3.2-vision:2b.Or switch to a machine with more RAM and expose Ollama to the network.
The code cannot connect to Ollama (connection refused).
Check the following:
Make sure Ollama is running (
ollama serveor the desktop app is open).If using a remote computer, enable Expose to network in Ollama settings.
Double-check that the
ip="..."in your code matches the correct LAN IP.Confirm both devices are on the same local network.