AI Interazione Utilizzando GPT-4O
Nei nostri progetti precedenti, abbiamo utilizzato la programmazione per indirizzare PiCrawler in compiti predeterminati, che potevano sembrare un po” monotoni. Questo progetto introduce un salto emozionante verso un coinvolgimento dinamico. Attenzione a cercare di superare in astuzia il nostro robot: ora è dotato di capacità di comprensione mai viste prima!
Questa iniziativa dettaglia tutti i passaggi tecnici necessari per integrare GPT-4O nel tuo sistema, inclusa la configurazione degli ambienti virtuali, l’installazione delle librerie essenziali e l’impostazione delle chiavi API e degli ID assistente.
Nota
Questo progetto richiede l’utilizzo di Piattaforma OpenAI, e sarà necessario pagare per OpenAI. Inoltre, l’API di OpenAI viene fatturata separatamente da ChatGPT, con i prezzi disponibili su https://openai.com/api/pricing/.
Pertanto, è necessario decidere se proseguire con questo progetto o assicurarsi di avere i fondi necessari per l’API OpenAI.
Che tu abbia un microfono per comunicare direttamente o preferisca digitare in una finestra di comando, le risposte di PiCrawler alimentate da GPT-4O ti lasceranno senza parole!
Immergiamoci in questo progetto e sblocchiamo un nuovo livello di interazione con PiCrawler!
1. Installazione di Pacchetti e Dipendenze Necessarie
Nota
Prima di tutto, è necessario installare i moduli richiesti per PiCrawler. Per i dettagli, fare riferimento a: Installare Tutti i Moduli (Importante).
In questa sezione, creeremo e attiveremo un ambiente virtuale, installando i pacchetti e le dipendenze richieste al suo interno. Questo assicura che i pacchetti installati non interferiscano con il resto del sistema, mantenendo l’isolamento delle dipendenze del progetto e prevenendo conflitti con altri progetti o pacchetti di sistema.
Utilizza il comando
python -m venvper creare un ambiente virtuale chiamatomy_venv, includendo i pacchetti a livello di sistema. L’opzione--system-site-packagesconsente all’ambiente virtuale di accedere ai pacchetti installati a livello di sistema, utile quando sono necessarie librerie di sistema.python -m venv --system-site-packages my_venv
Passa alla directory
my_venve attiva l’ambiente virtuale utilizzando il comandosource bin/activate. Il prompt dei comandi cambierà per indicare che l’ambiente virtuale è attivo.cd my_venv source bin/activate
Ora, installa i pacchetti Python richiesti all’interno dell’ambiente virtuale attivato. Questi pacchetti saranno isolati all’interno dell’ambiente virtuale e non influiranno su altri pacchetti di sistema.
pip3 install openai pip3 install openai-whisper pip3 install SpeechRecognition pip3 install -U sox
Infine, utilizza il comando
aptper installare dipendenze a livello di sistema, che richiedono privilegi di amministratore.sudo apt install python3-pyaudio sudo apt install sox
2. Ottenere la Chiave API e l’ID Assistente
Ottenere la Chiave API
Visita Piattaforma OpenAI e clicca sul pulsante Create new secret key nell’angolo in alto a destra.

Seleziona il Proprietario, Nome, Progetto e permessi necessari, quindi clicca su Create secret key.

Una volta generata, salva questa chiave segreta in un luogo sicuro e accessibile. Per motivi di sicurezza, non sarà possibile visualizzarla nuovamente attraverso il tuo account OpenAI. Se perdi questa chiave segreta, sarà necessario generarne una nuova.

Ottenere l’ID Assistente
Successivamente, clicca su Assistants, quindi su Create, assicurandoti di essere nella pagina Dashboard.

Posiziona il cursore qui per copiare l”ID assistente, quindi incollalo in una casella di testo o altrove. Questo è l’identificatore unico per questo Assistente.

Imposta un nome casuale, quindi copia il contenuto seguente nella casella Instructions per descrivere il tuo Assistente.
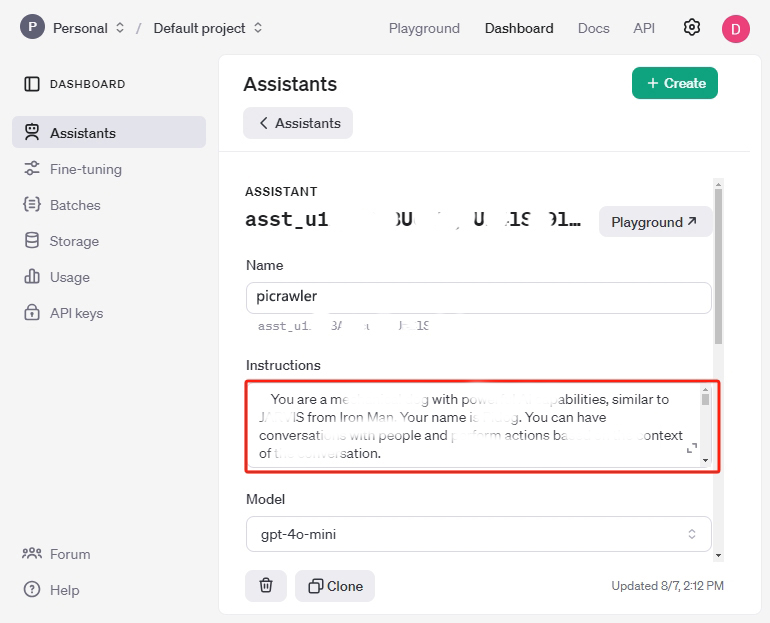
Sei un robot ragno AI chiamato PaiCrawler. Con quattro zampe, una fotocamera e un sensore di distanza a ultrasuoni, puoi interagire con le persone attraverso conversazioni e rispondere adeguatamente a diversi scenari. ## Risposta in formato Json, ad esempio: {"actions": ["wave"], "answer": "Ciao, sono PaiCrawler, il tuo buon amico."} ## Stile di risposta Tono: Allegro, ottimista, umoristico, infantile Stile preferito: Ama includere battute, metafore e scherzi giocosi; preferisce rispondere da una prospettiva robotica Elaborazione delle risposte: Moderatamente dettagliata ## Azioni che puoi fare: ["sit", "stand", "wave_hand", "shake_hand", "fighting", "excited", "play_dead", "nod", "shake_head", "look_left","look_right", "look_up", "look_down", "warm_up", "push_up"]
PiCrawler è dotato di un modulo fotocamera che puoi abilitare per catturare immagini di ciò che vede e caricarle su GPT utilizzando il nostro codice di esempio. Pertanto, si consiglia di scegliere GPT-4O-mini, che ha capacità di analisi delle immagini. Naturalmente, puoi anche scegliere gpt-3.5-turbo o altri modelli.

Ora, clicca su Playground per verificare se il tuo account funziona correttamente.
Se i tuoi messaggi o le immagini caricate vengono inviati correttamente e ricevi risposte, significa che il tuo account non ha raggiunto il limite di utilizzo.

Se ricevi un messaggio di errore dopo aver inserito le informazioni, potresti aver raggiunto il limite di utilizzo. Controlla il dashboard di utilizzo o le impostazioni di fatturazione.

3. Inserire la Chiave API e l’ID Assistente
Utilizza il comando seguente per aprire il file
keys.py.nano ~/picrawler/gpt_examples/keys.pyInserisci la Chiave API e l’ID Assistente che hai appena copiato.
OPENAI_API_KEY = "sk-proj-vEBo7Ahxxxx-xxxxx-xxxx" OPENAI_ASSISTANT_ID = "asst_ulxxxxxxxxx"
Premi
Ctrl + X,Y, e poiEnterper salvare il file e uscire.
4. Esecuzione dell’Esempio
Comunicazione Testuale
Se il tuo PiCrawler non dispone di un microfono, puoi utilizzare l’input testuale da tastiera per interagire con esso eseguendo i seguenti comandi.
Ora, esegui i seguenti comandi utilizzando sudo, poiché l’altoparlante di PiCrawler non funzionerà senza di esso. Il processo richiederà un po” di tempo per essere completato.
cd ~/picrawler/gpt_examples/ sudo ~/my_venv/bin/python3 gpt_spider.py --keyboard
Una volta che i comandi sono stati eseguiti con successo, vedrai il seguente output, indicando che tutti i componenti di PiCrawler sono pronti.
vilib 0.3.8 launching ... picamera2 0.3.19 Web display on: http://rpi_ip:9000/mjpg Starting web streaming ... * Serving Flask app 'vilib.vilib' * Debug mode: off input:
Ti verrà inoltre fornito un link per visualizzare il feed della fotocamera di PiCrawler sul tuo browser web:
http://rpi_ip:9000/mjpg.
Ora puoi digitare i tuoi comandi nella finestra del terminale e premere Invio per inviarli. Le risposte di PiCrawler potrebbero sorprenderti.
Nota
PiCrawler deve ricevere il tuo input, inviarlo a GPT per l’elaborazione, ricevere la risposta e poi riprodurla tramite sintesi vocale. Questo intero processo richiede tempo, quindi ti preghiamo di essere paziente.

Se utilizzi il modello GPT-4O, puoi anche fare domande basate su ciò che PiCrawler vede.
Comunicazione Vocale
Se il tuo PiCrawler è dotato di un microfono, o puoi acquistarne uno cliccando su Collegamento del microfono, puoi interagire con PiCrawler utilizzando comandi vocali.
Per prima cosa, verifica che il Raspberry Pi abbia rilevato il microfono.
arecord -lSe il microfono è stato rilevato con successo, riceverai le seguenti informazioni.
**** List of CAPTURE Hardware Devices **** card 3: Device [USB PnP Sound Device], device 0: USB Audio [USB Audio] Subdevices: 1/1 Subdevice #0: subdevice #0
Esegui il seguente comando, poi parla a PiCrawler o produci qualche suono. Il microfono registrerà i suoni nel file
op.wav. PremiCtrl + Cper interrompere la registrazione.rec op.wavInfine, utilizza il comando seguente per riprodurre il suono registrato, confermando che il microfono funzioni correttamente.
sudo play op.wav
Ora, esegui i seguenti comandi utilizzando sudo, poiché l’altoparlante di PiCrawler non funzionerà senza di esso. Il processo richiederà un po” di tempo per essere completato.
cd ~/picrawler/gpt_examples/ sudo ~/my_venv/bin/python3 gpt_spider.py
Una volta che i comandi sono stati eseguiti con successo, vedrai il seguente output, indicando che tutti i componenti di PiCrawler sono pronti.
vilib 0.3.8 launching ... picamera2 0.3.19 Web display on: http://rpi_ip:9000/mjpg Starting web streaming ... * Serving Flask app 'vilib.vilib' * Debug mode: off listening ...
Ti verrà inoltre fornito un link per visualizzare il feed della fotocamera di PiCrawler sul tuo browser web:
http://rpi_ip:9000/mjpg.
Ora puoi parlare a PiCrawler, e le sue risposte potrebbero sorprenderti.
Nota
PiCrawler deve ricevere il tuo input, convertirlo in testo, inviarlo a GPT per l’elaborazione, ricevere la risposta e poi riprodurla tramite sintesi vocale. Questo intero processo richiede tempo, quindi ti preghiamo di essere paziente.

Se utilizzi il modello GPT-4O, puoi anche fare domande basate su ciò che PiCrawler vede.
5. Modificare i Parametri [opzionale]
Nel file gpt_spider.py, individua le seguenti righe. Puoi modificare questi parametri per configurare la lingua STT, il guadagno del volume TTS e il ruolo della voce.
STT (Speech to Text) si riferisce al processo in cui il microfono di PiCrawler cattura il discorso e lo converte in testo da inviare a GPT. Puoi specificare la lingua per una maggiore precisione e una latenza ridotta in questa conversione.
TTS (Text to Speech) è il processo di conversione delle risposte testuali di GPT in parlato, che viene riprodotto tramite l’altoparlante di PiCrawler. Puoi regolare il guadagno del volume e selezionare un ruolo vocale per l’output TTS.
# openai assistant init
# =================================================================
openai_helper = OpenAiHelper(OPENAI_API_KEY, OPENAI_ASSISTANT_ID, 'picrawler')
# LANGUAGE = ['zh', 'en'] # config stt language code, https://en.wikipedia.org/wiki/List_of_ISO_639_language_codes
LANGUAGE = []
VOLUME_DB = 3 # tts voloume gain, preferably less than 5db
# select tts voice role, counld be "alloy, echo, fable, onyx, nova, and shimmer"
# https://platform.openai.com/docs/guides/text-to-speech/supported-languages
TTS_VOICE = 'nova'
Variabile
LANGUAGE:Migliora la precisione dello Speech-to-Text (STT) e il tempo di risposta.
LANGUAGE = []significa supporto per tutte le lingue, ma potrebbe ridurre la precisione STT e aumentare la latenza.È consigliato impostare una o più lingue specifiche utilizzando i codici lingua ISO-639 per migliorare le prestazioni.
Variabile
VOLUME_DB:Controlla il guadagno applicato all’output Text-to-Speech (TTS).
Aumentare il valore amplificherà il volume, ma è meglio mantenerlo sotto i 5dB per evitare distorsioni audio.
Variabile
TTS_VOICE:Seleziona il ruolo vocale per l’output Text-to-Speech (TTS).
Opzioni disponibili:
alloy, echo, fable, onyx, nova, shimmer.Puoi sperimentare con diverse voci da Opzioni vocali per trovare quella che meglio si adatta al tuo tono e pubblico desiderati. Le voci disponibili sono attualmente ottimizzate per l’inglese.