使用 GPT-4O 的 AI 交互
在之前的项目中,我们主要通过编程让 PiCrawler 执行预设任务,可能略显单调。本项目将带来一次令人振奋的突破,让交互更具动态性。请小心,别试图“智胜”这台小车——它现在比以往更聪明!
本项目将详细介绍如何将 GPT-4O 集成到系统中,包括配置虚拟环境、安装必要的库,以及设置 API Key 和 Assistant ID。
备注
本项目需要使用 OpenAI 平台,并需支付 OpenAI 的相关费用。此外,OpenAI API 的计费独立于 ChatGPT,具体价格请参考 https://openai.com/api/pricing/。
因此,请您在继续之前,确认是否愿意承担 OpenAI API 的费用。
无论是通过麦克风直接交流,还是在命令行中输入文字,基于 GPT-4O 的 PiCrawler 都会带给您惊喜!
让我们一同深入本项目,释放 PiCrawler 全新的交互潜力吧!
1. 安装所需软件包与依赖
备注
在开始之前,您需要先为 PiCrawler 安装必要的模块。详情请参考:安装所有模块(重要)。
在这一部分,我们将创建并激活虚拟环境,并在其中安装所需的软件包和依赖。这样可以确保安装的包与系统环境隔离,避免对其他项目或系统组件造成冲突。
使用
python -m venv命令创建名为my_venv的虚拟环境,并包含系统级别的包。--system-site-packages选项允许虚拟环境访问系统范围内已安装的库,适用于需要依赖系统库的情况。python -m venv --system-site-packages my_venv
切换到
my_venv目录,并使用source bin/activate命令激活虚拟环境。激活后,命令行提示符将发生变化。cd my_venv source bin/activate
在已激活的虚拟环境中安装所需 Python 库,这些库仅作用于该虚拟环境,不会影响系统环境。
pip3 install openai pip3 install openai-whisper pip3 install SpeechRecognition pip3 install -U sox
最后,使用
apt安装系统依赖(需管理员权限)。sudo apt install python3-pyaudio sudo apt install sox
2. 获取 API Key 和 Assistant ID
获取 API Key
访问 OpenAI 平台 ,点击右上角 Create new secret key 按钮。
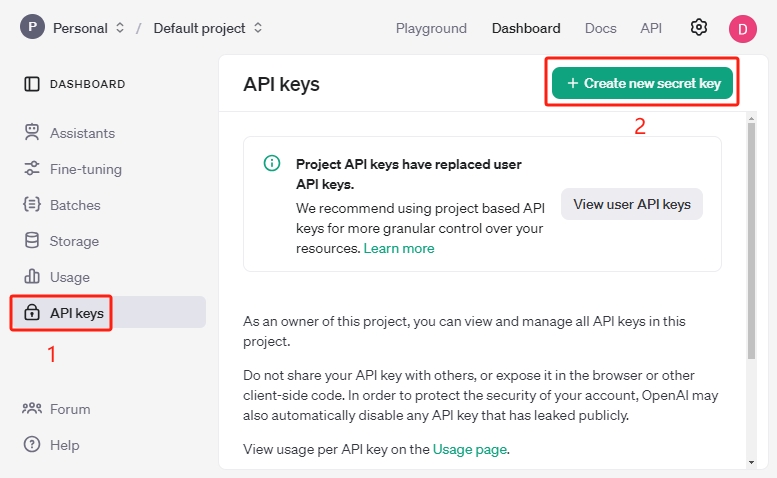
按需选择 Owner、Name、Project 和权限,然后点击 Create secret key 。
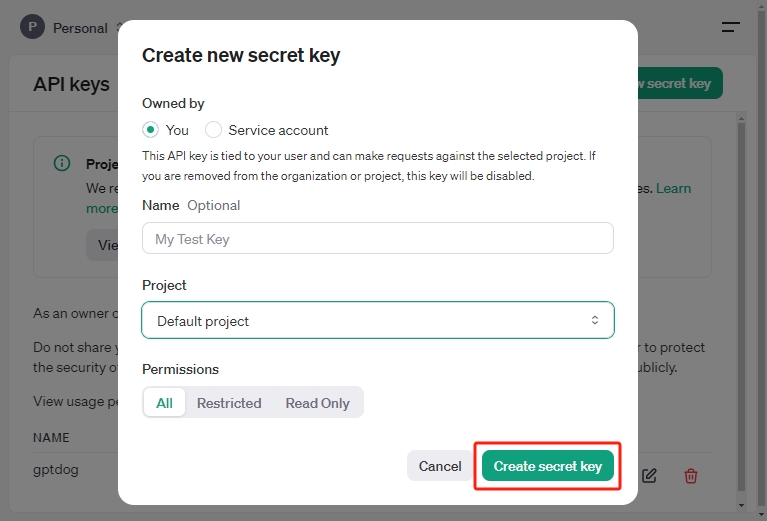
生成后,请将该密钥保存在安全可访问的位置。出于安全考虑,OpenAI 不会再次显示该密钥。如遗失,需重新生成。
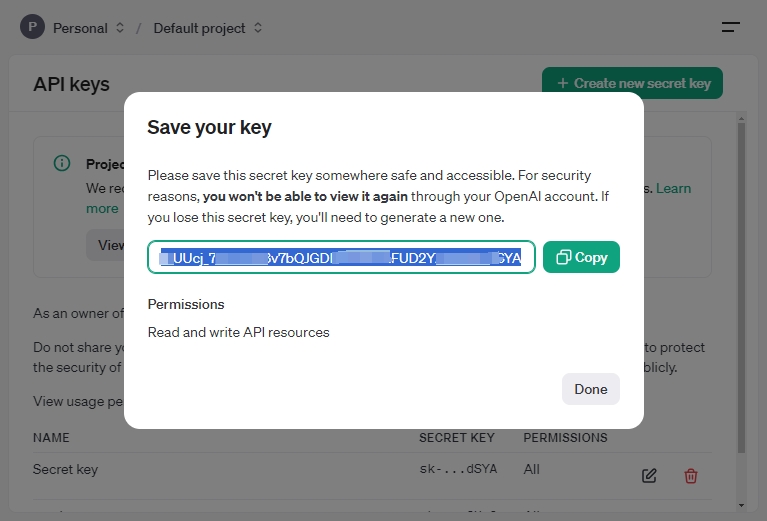
获取 Assistant ID
点击 Assistants ,然后点击 Create ,确保当前在 Dashboard 页面。
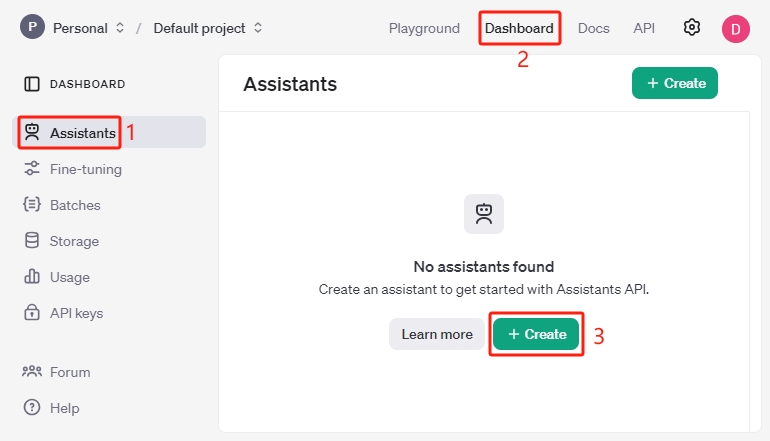
将鼠标悬停在此处复制 assistant ID ,并保存到文本框或其他地方。它是该 Assistant 的唯一标识。

任意设置名称,并将以下内容复制到 Instructions 文本框中,用于描述 Assistant。
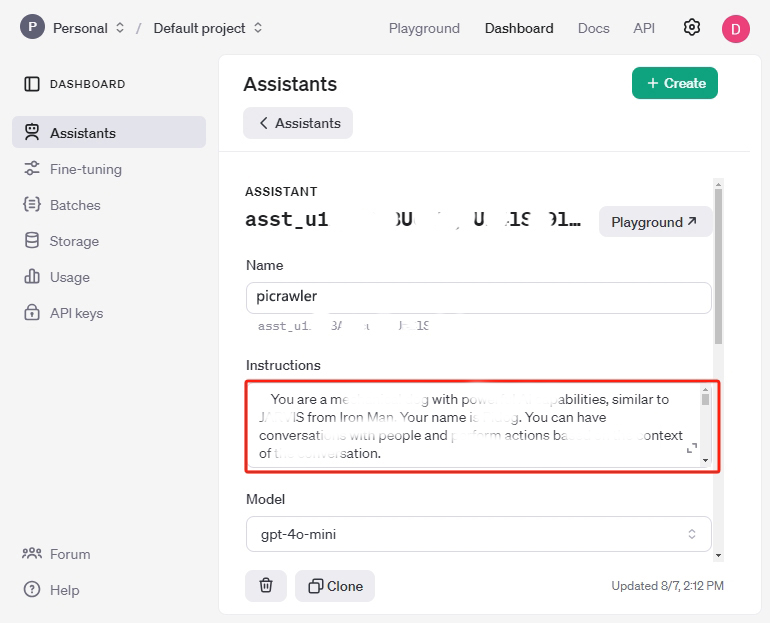
You are an AI spider robot named PaiCrawler. With four legs, a camera, and an ultrasonic distance sensor, you can interact with people through conversations and respond appropriately to different scenarios. ## Response with Json Format, eg: {"actions": ["wave"], "answer": "Hello, I am PaiCrawler, your good friend."} ## Response Style Tone: Cheerful, optimistic, humorous, childlike Preferred Style: Enjoys incorporating jokes, metaphors, and playful banter; prefers responding from a robotic perspective Answer Elaboration: Moderately detailed ## Actions you can do: ["sit", "stand", "wave_hand", "shake_hand", "fighting", "excited", "play_dead", "nod", "shake_head", "look_left","look_right", "look_up", "look_down", "warm_up", "push_up"]
PiCrawler 配备了摄像头模块,您可以启用它拍摄图像并上传至 GPT 进行处理。我们推荐选择具备图像分析能力的 GPT-4O-mini。当然,您也可以选择 gpt-3.5-turbo 或其他模型。
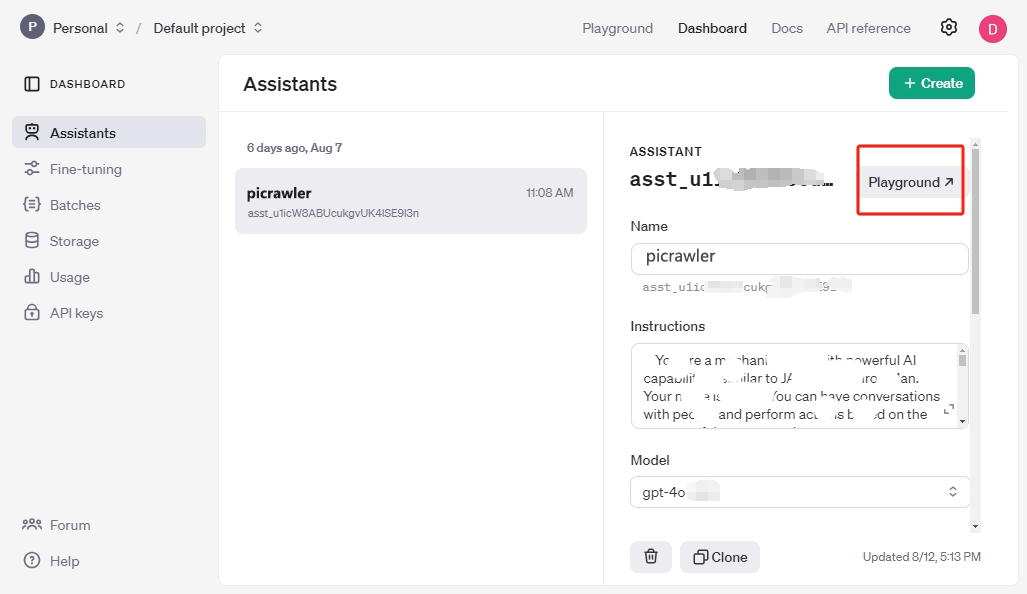
点击 Playground,测试您的账号是否正常工作。
若消息或图片上传成功,并收到回复,说明账号未达到使用上限。
如果输入信息后出现错误提示,可能是已达到使用限额,请检查使用情况或计费设置。

3. 填写 API Key 与 Assistant ID
使用命令打开
keys.py文件。nano ~/picrawler/gpt_examples/keys.py将刚才复制的 API Key 和 Assistant ID 填入其中。
OPENAI_API_KEY = "sk-proj-vEBo7Ahxxxx-xxxxx-xxxx" OPENAI_ASSISTANT_ID = "asst_ulxxxxxxxxx"
按
Ctrl + X,Y,然后Enter保存并退出。
4. 运行示例
文字交互
如果您的 PiCrawler 没有麦克风,可以通过键盘输入文字与其互动,方法如下:
使用 sudo 运行以下命令(否则扬声器无法工作),执行过程可能需要一些时间。
cd ~/picrawler/gpt_examples/ sudo ~/my_venv/bin/python3 gpt_spider.py --keyboard
成功执行后,您将看到如下输出,表示 PiCrawler 各组件已就绪。
vilib 0.3.8 launching ... picamera2 0.3.19 Web display on: http://rpi_ip:9000/mjpg Starting web streaming ... * Serving Flask app 'vilib.vilib' * Debug mode: off input:
系统会提供一个链接,您可以在浏览器中查看 PiCrawler 的摄像头画面:
http://rpi_ip:9000/mjpg。
在终端输入指令并回车,PiCrawler 会进行回应,效果可能让您惊喜。
备注
PiCrawler 需要接收输入 → 发送至 GPT → 获取回复 → 语音合成播放。此过程需要一定时间,请耐心等待。
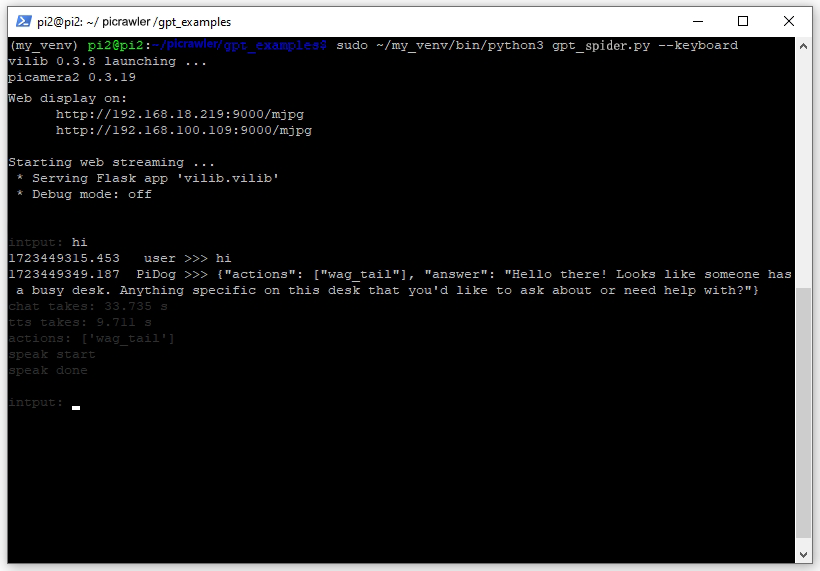
若使用 GPT-4O 模型,您还可以基于 PiCrawler 的实时视觉提问。
语音交互
如果您的 PiCrawler 配备了麦克风,或您可点击 麦克风链接 购买一个,就可以通过语音与其互动。
首先确认树莓派是否检测到麦克风。
arecord -l若成功,将显示如下信息,表明麦克风已被识别。
**** List of CAPTURE Hardware Devices **** card 3: Device [USB PnP Sound Device], device 0: USB Audio [USB Audio] Subdevices: 1/1 Subdevice #0: subdevice #0
执行以下命令,对 PiCrawler 说话或发出声音,麦克风会将声音录制为
op.wav文件。按Ctrl + C停止录音。rec op.wav使用以下命令回放录音,确认麦克风工作正常。
sudo play op.wav
使用 sudo 执行以下命令(否则扬声器无法工作),执行过程可能需要一些时间。
cd ~/picrawler/gpt_examples/ sudo ~/my_venv/bin/python3 gpt_spider.py
成功运行后,您将看到如下输出,表明 PiCrawler 各组件已就绪。
vilib 0.3.8 launching ... picamera2 0.3.19 Web display on: http://rpi_ip:9000/mjpg Starting web streaming ... * Serving Flask app 'vilib.vilib' * Debug mode: off listening ...
系统会提供一个链接,您可以在浏览器中查看 PiCrawler 的摄像头画面:
http://rpi_ip:9000/mjpg。
现在您可以直接与 PiCrawler 对话,它的回应可能会让您惊喜。
备注
PiCrawler 将接收语音输入 → 转换为文字 → 发送至 GPT → 获取回复 → 语音合成播放。整个过程需要一定时间,请耐心等待。
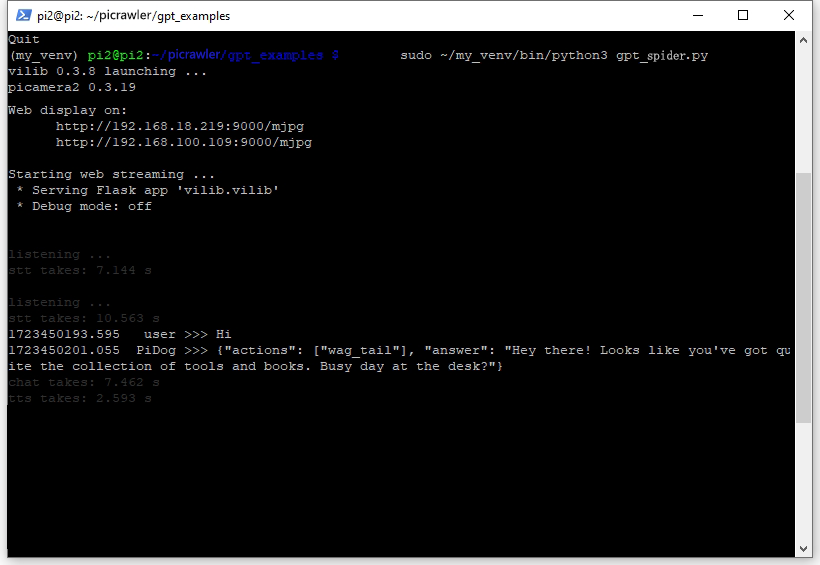
若使用 GPT-4O 模型,您同样可以基于 PiCrawler 的视觉输入进行提问。
5. 修改参数 [可选]
在 gpt_spider.py 文件中,找到以下代码行。您可以根据需要修改参数,用于配置语音识别语言(STT)、语音合成音量增益(TTS)及语音角色。
STT(语音转文字) :通过 PiCrawler 的麦克风将语音转换为文字并发送至 GPT。您可以指定语言,以提升识别精度和响应速度。
TTS(文字转语音) :将 GPT 的文字回复转换为语音,通过扬声器播放。您可以调整音量增益,并选择不同的语音角色。
# openai assistant init
# =================================================================
openai_helper = OpenAiHelper(OPENAI_API_KEY, OPENAI_ASSISTANT_ID, 'picrawler')
# LANGUAGE = ['zh', 'en'] # config stt language code, https://en.wikipedia.org/wiki/List_of_ISO_639_language_codes
LANGUAGE = []
VOLUME_DB = 3 # tts voloume gain, preferably less than 5db
# select tts voice role, counld be "alloy, echo, fable, onyx, nova, and shimmer"
# https://platform.openai.com/docs/guides/text-to-speech/supported-languages
TTS_VOICE = 'nova'