AIインタラクションの実現:GPT-4Oの使用
これまでのプロジェクトでは、予め決められたタスクに従ってPiCrawlerをプログラムで操作していましたが、それは少し退屈に感じることもありました。このプロジェクトでは、ダイナミックなインタラクションの新たな一歩を踏み出します。PiCrawlerは、これまで以上に多くのことを理解できるようになったため、その知恵を侮らないようにしましょう!
このプロジェクトでは、GPT-4Oをシステムに統合するための技術的な手順をすべて説明します。これには、必要な仮想環境の設定、必須ライブラリのインストール、APIキーとアシスタントIDの設定が含まれます。
注釈
このプロジェクトには OpenAIプラットフォーム の使用が必要で、OpenAIの料金が発生します。さらに、OpenAI APIはChatGPTとは別に料金が設定されており、料金については https://openai.com/api/pricing/ で確認できます。
そのため、このプロジェクトを続けるか、OpenAI APIの費用を支払ったことを確認する必要があります。
マイクを使って直接コミュニケーションを取ることも、コマンドウィンドウに入力することを好む場合も、GPT-4Oを使ったPiCrawlerの反応はきっと驚くべきものとなるでしょう!
さあ、このプロジェクトを始めて、PiCrawlerとの新しいインタラクションのレベルを解き放ちましょう!
1. 必要なパッケージと依存関係のインストール
注釈
まず、PiCrawlerに必要なモジュールをインストールする必要があります。詳細については、すべてのモジュールをインストールする(重要) を参照してください。
このセクションでは、仮想環境を作成して有効化し、その中で必要なパッケージと依存関係をインストールします。これにより、インストールしたパッケージがシステムに干渉せず、プロジェクト間で依存関係の競合を防ぐことができます。
python -m venvコマンドを使用して、my_venvという名前の仮想環境を作成します。--system-site-packagesオプションを使用すると、システム全体にインストールされたパッケージにもアクセスでき、システムレベルのライブラリが必要な場合に役立ちます。python -m venv --system-site-packages my_venv
my_venvディレクトリに移動し、source bin/activateコマンドで仮想環境を有効化します。コマンドプロンプトが変わり、仮想環境が有効になったことを示します。cd my_venv source bin/activate
次に、有効化した仮想環境内に必要なPythonパッケージをインストールします。これらのパッケージは仮想環境内に隔離され、システムの他のパッケージには影響を与えません。
pip3 install openai pip3 install openai-whisper pip3 install SpeechRecognition pip3 install -U sox
最後に、
aptコマンドを使用してシステムレベルの依存関係をインストールします。この操作には管理者権限が必要です。sudo apt install python3-pyaudio sudo apt install sox
2. APIキーとアシスタントIDの取得
APIキーの取得
OpenAIプラットフォーム にアクセスし、右上隅の 新しい秘密キーを作成 ボタンをクリックします。
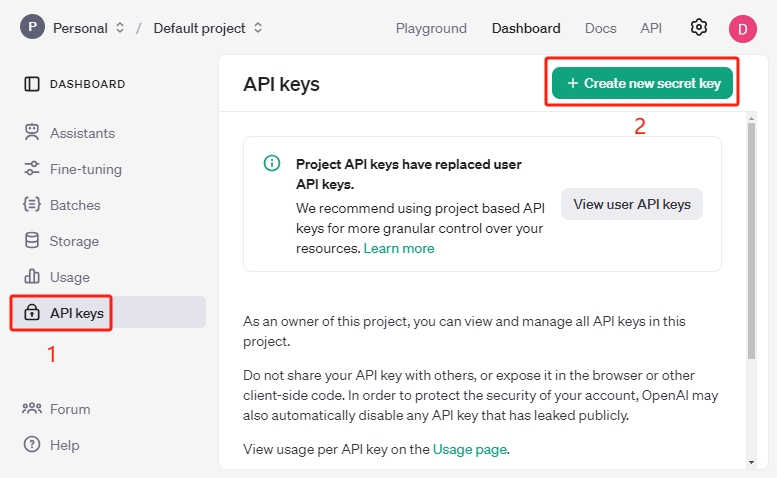
必要に応じてオーナー、名前、プロジェクト、権限を選択し、 秘密キーを作成 をクリックします。
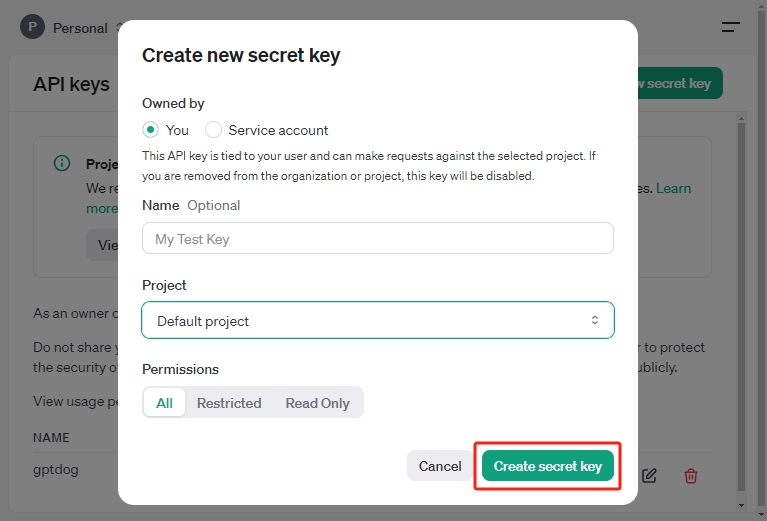
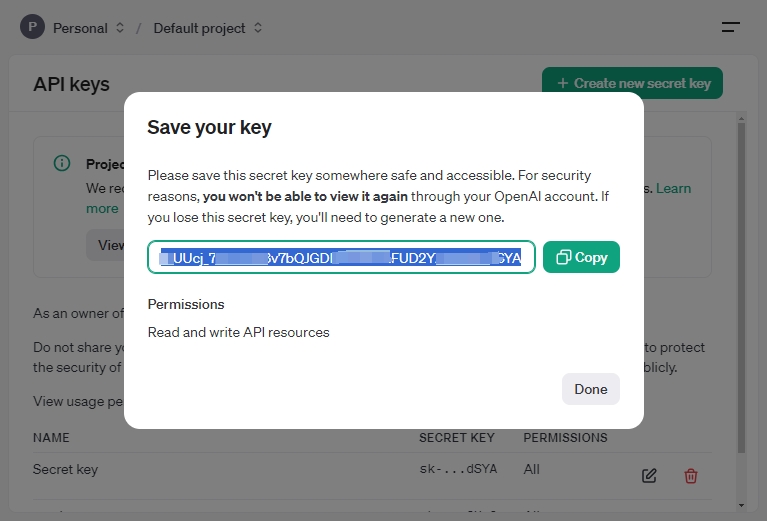
秘密キーが生成されたら、安全でアクセスしやすい場所に保存してください。セキュリティ上の理由から、OpenAIアカウントでは再度表示することはできません。この秘密キーを失うと、新しいキーを生成する必要があります。
アシスタントIDの取得
次に、 アシスタント をクリックし、 作成 をクリックします。必ず ダッシュボード ページにいることを確認してください。
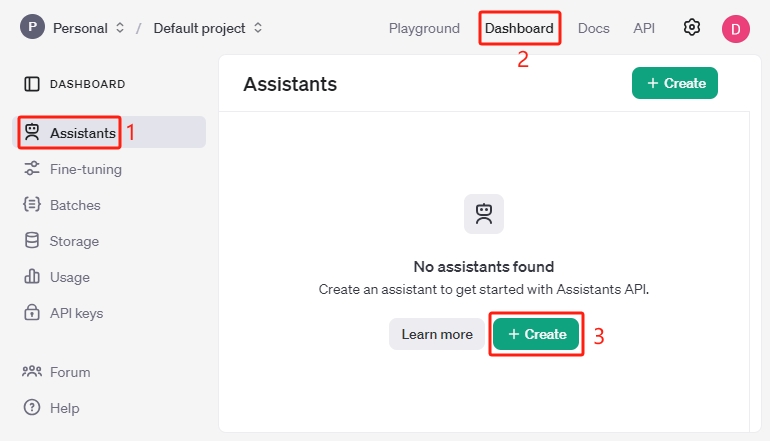
ここで アシスタントID をコピーし、テキストボックスや別の場所に貼り付けます。これはこのアシスタントの一意の識別子です。
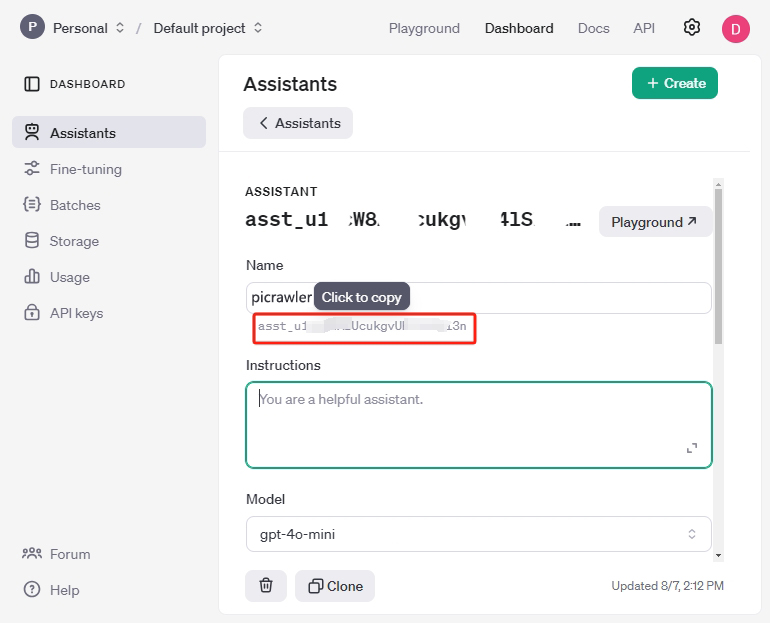
ランダムな名前を設定し、以下の内容を 指示 ボックスにコピーしてアシスタントを説明します。

You are an AI spider robot named PaiCrawler. With four legs, a camera, and an ultrasonic distance sensor, you can interact with people through conversations and respond appropriately to different scenarios. ## Response with Json Format, eg: {"actions": ["wave"], "answer": "Hello, I am PaiCrawler, your good friend."} ## Response Style Tone: Cheerful, optimistic, humorous, childlike Preferred Style: Enjoys incorporating jokes, metaphors, and playful banter; prefers responding from a robotic perspective Answer Elaboration: Moderately detailed ## Actions you can do: ["sit", "stand", "wave_hand", "shake_hand", "fighting", "excited", "play_dead", "nod", "shake_head", "look_left","look_right", "look_up", "look_down", "warm_up", "push_up"]
PiCrawlerにはカメラモジュールが搭載されており、これを有効にして、PiCrawlerが見た画像をキャプチャし、例のコードを使用してGPTにアップロードできます。そのため、画像解析機能を持つGPT-4O-miniを選択することをお勧めします。もちろん、gpt-3.5-turboや他のモデルを選ぶこともできます。

次に、 Playground をクリックして、アカウントが正常に機能しているか確認します。
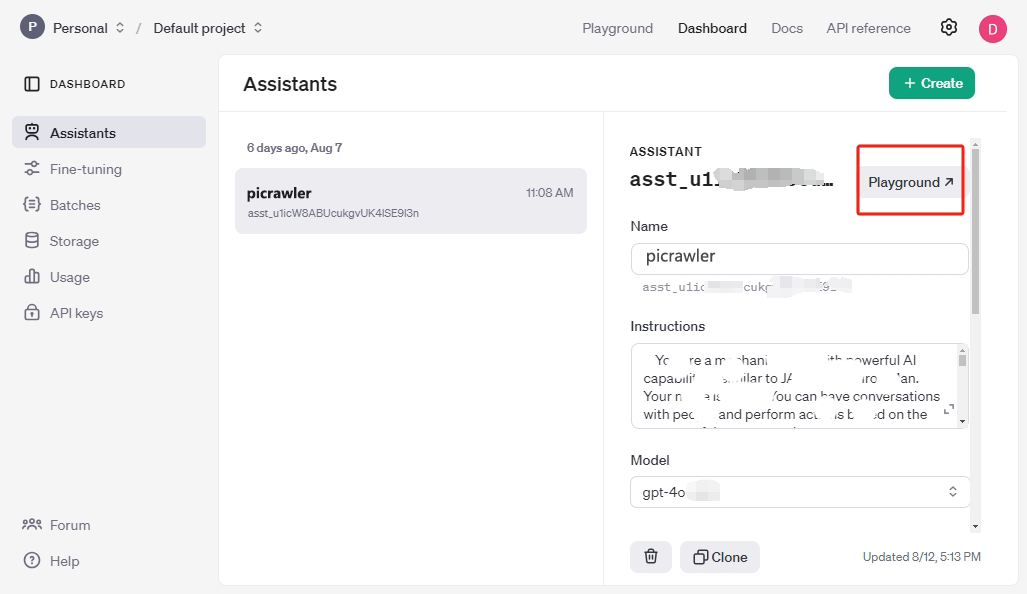
メッセージやアップロードした画像が正常に送信され、返信があれば、アカウントが使用制限に達していないことを意味します。
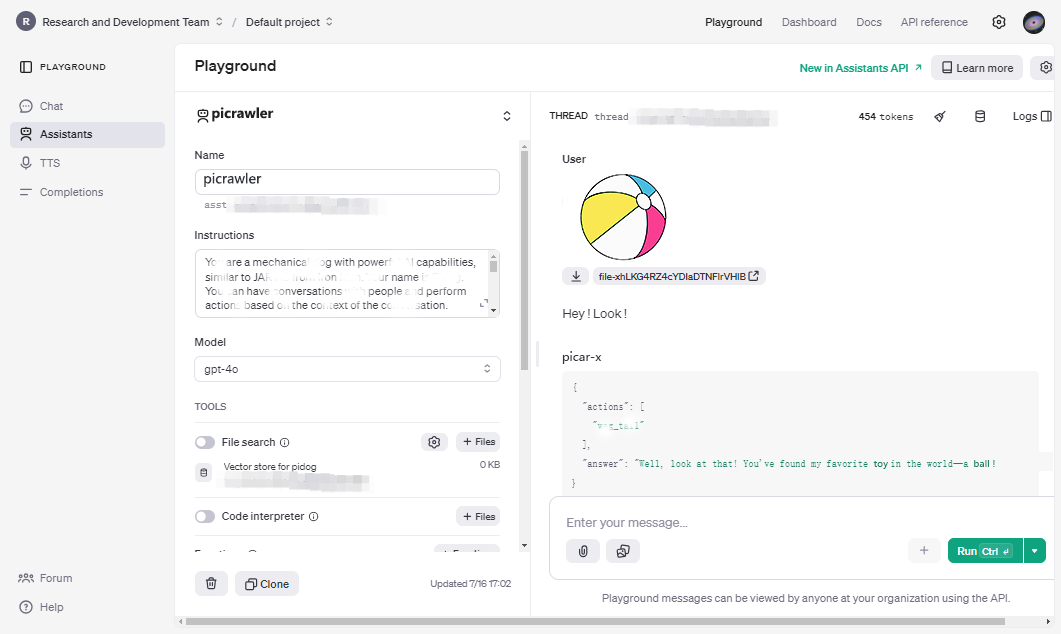
情報を入力した後にエラーメッセージが表示された場合、使用制限に達している可能性があります。使用ダッシュボードや請求設定を確認してください。
3. APIキーとアシスタントIDの入力
keys.pyファイルを開くコマンドを使用します。nano ~/picrawler/gpt_examples/keys.py先ほどコピーしたAPIキーとアシスタントIDを入力します。
OPENAI_API_KEY = "sk-proj-vEBo7Ahxxxx-xxxxx-xxxx" OPENAI_ASSISTANT_ID = "asst_ulxxxxxxxxx"
Ctrl + X,Y,Enterを押して、ファイルを保存して終了します。
4. サンプルコードの実行
テキスト通信
PiCrawlerにマイクが搭載されていない場合は、以下のコマンドを実行してキーボード入力によるインタラクションを行うことができます。
次に、以下のコマンドをsudoを使用して実行します。PiCrawlerのスピーカーはsudoなしでは機能しないためです。このプロセスには少し時間がかかります。
cd ~/picrawler/gpt_examples/ sudo ~/my_venv/bin/python3 gpt_spider.py --keyboard
コマンドが正常に実行されると、以下の出力が表示され、PiCrawlerのすべてのコンポーネントが準備完了であることが示されます。
vilib 0.3.8 launching ... picamera2 0.3.19 Web display on: http://rpi_ip:9000/mjpg Starting web streaming ... * Serving Flask app 'vilib.vilib' * Debug mode: off input:
また、PiCrawlerのカメラ映像をウェブブラウザで表示するためのリンクも提供されます:
http://rpi_ip:9000/mjpg。
今、ターミナルウィンドウにコマンドを入力して、Enterを押して送信できます。PiCrawlerの反応はあなたを驚かせるかもしれません。
注釈
PiCrawlerはあなたの入力を受け取り、それをGPTに送信して処理し、応答を受け取った後、音声合成で再生します。この一連のプロセスには時間がかかるため、しばらくお待ちください。
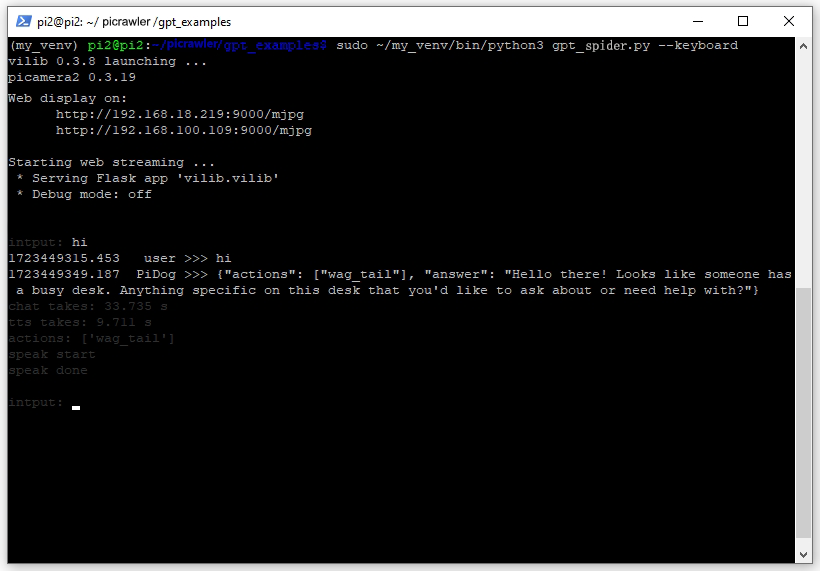
GPT-4Oモデルを使用している場合は、PiCrawlerが見たものに基づいて質問することもできます。
音声通信
PiCrawlerにマイクが搭載されている場合、または|link_microphone|をクリックして購入できる場合、音声コマンドを使ってPiCrawlerとインタラクションできます。
まず、Raspberry Piがマイクを検出しているか確認します。
arecord -l成功すれば、以下の情報が表示され、マイクが正常に検出されたことが確認できます。
**** List of CAPTURE Hardware Devices **** card 3: Device [USB PnP Sound Device], device 0: USB Audio [USB Audio] Subdevices: 1/1 Subdevice #0: subdevice #0
以下のコマンドを実行し、PiCrawlerに向かって話しかけるか、音を出します。マイクはその音を
op.wavファイルに録音します。録音を終了するにはCtrl + Cを押します。rec op.wav最後に、以下のコマンドを使って録音した音を再生し、マイクが正常に動作していることを確認します。
sudo play op.wav
次に、以下のコマンドをsudoで実行します。PiCrawlerのスピーカーはsudoなしでは機能しないためです。このプロセスには少し時間がかかります。
cd ~/picrawler/gpt_examples/ sudo ~/my_venv/bin/python3 gpt_spider.py
コマンドが正常に実行されると、以下の出力が表示され、PiCrawlerのすべてのコンポーネントが準備完了であることが示されます。
vilib 0.3.8 launching ... picamera2 0.3.19 Web display on: http://rpi_ip:9000/mjpg Starting web streaming ... * Serving Flask app 'vilib.vilib' * Debug mode: off listening ...
PiCrawlerのカメラ映像をウェブブラウザで表示するためのリンクも提供されます:
http://rpi_ip:9000/mjpg。
今、PiCrawlerに話しかけることができ、その反応はあなたを驚かせるかもしれません。
注釈
PiCrawlerはあなたの入力を受け取り、それをテキストに変換し、GPTに送信して処理し、応答を受け取った後、音声合成で再生します。この一連のプロセスには時間がかかるため、しばらくお待ちください。
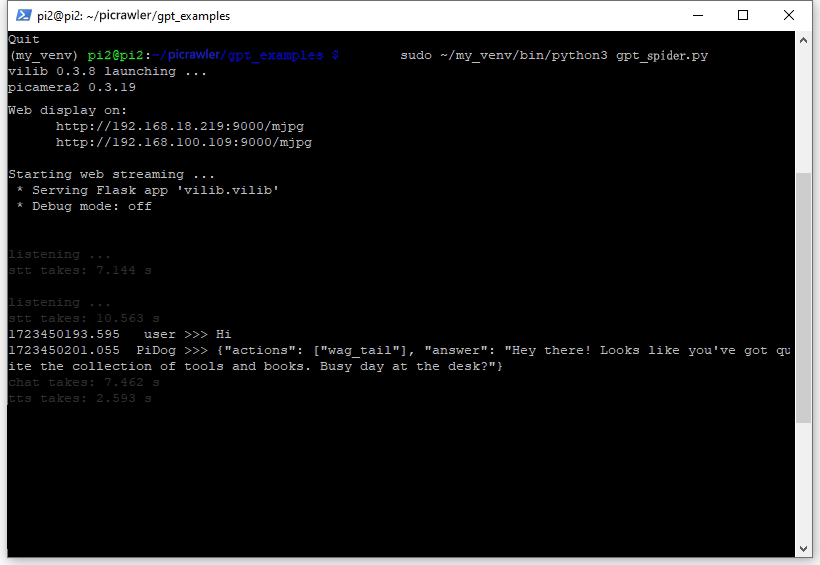
GPT-4Oモデルを使用している場合は、PiCrawlerが見たものに基づいて質問することもできます。
パラメータの変更 [オプション]
gpt_spider.py ファイルで、以下の行を探します。これらのパラメータを変更して、STT(音声認識)言語、TTS(音声合成)の音量ゲイン、音声の役割を設定できます。
STT(音声からテキストへの変換) は、PiCrawlerのマイクが音声をキャプチャし、それをテキストに変換してGPTに送信するプロセスです。変換精度と遅延を改善するために、言語を指定できます。
TTS(テキストから音声への変換) は、GPTのテキスト応答を音声に変換し、それをPiCrawlerのスピーカーで再生するプロセスです。音量ゲインを調整したり、音声の役割を選択したりできます。
# openai assistant init
# =================================================================
openai_helper = OpenAiHelper(OPENAI_API_KEY, OPENAI_ASSISTANT_ID, 'picrawler')
# LANGUAGE = ['zh', 'en'] # STTの言語コード設定、https://en.wikipedia.org/wiki/List_of_ISO_639_language_codes
LANGUAGE = []
VOLUME_DB = 3 # TTSの音量ゲイン、理想的には5dB未満
# TTS音声役割を選択、"alloy", "echo", "fable", "onyx", "nova", "shimmer"など
# https://platform.openai.com/docs/guides/text-to-speech/supported-languages
TTS_VOICE = 'nova'
LANGUAGE変数:音声認識(STT)の精度と応答速度を改善します。
LANGUAGE = []はすべての言語をサポートしますが、これによりSTTの精度が低下し、遅延が増加する可能性があります。パフォーマンスを向上させるために、 ISO-639 の言語コードを使用して特定の言語を設定することをお勧めします。
VOLUME_DB変数:TTS出力に適用される音量ゲインを制御します。
値を大きくすると音量が増加しますが、音声歪みを防ぐために5dB未満に設定することをお勧めします。
TTS_VOICE変数:TTS出力の音声役割を選択します。
利用可能なオプション:
alloy, echo, fable, onyx, nova, shimmer。音声オプション でさまざまな音声を試して、希望するトーンや対象に適したものを見つけてください。現在、利用可能な音声は英語に最適化されています。