注釈
こんにちは、SunFounder Raspberry Pi & Arduino & ESP32 Enthusiast Community on Facebookへようこそ!他の愛好家と一緒に、Raspberry Pi、Arduino、ESP32の世界により深く入り込みましょう。
参加する理由
専門家サポート: 購入後の問題や技術的な課題を、コミュニティと私たちのチームの助けを借りて解決します。
学習と共有: ヒントやチュートリアルを交換して、スキルを向上させましょう。
限定プレビュー: 新製品の発表や先行プレビューに早期アクセスできます。
特別割引: 最新製品を特別割引でお楽しみいただけます。
季節限定キャンペーンとプレゼント: プレゼント企画やホリデーキャンペーンに参加しましょう。
👉 一緒に発見し、創造する準備はできましたか? [こちら] をクリックして、今すぐ参加しましょう!
2. YOLOEによる全物体検出
YOLOE(You Only Look Once with Embeddings)はYOLOファミリーの最新メンバーであり、伝統的なYOLOに言語-画像の共同学習機能を導入しています。簡単に言うと、YOLOEはトレーニングされた物体だけでなく、テキスト説明やプロンプトを通じて任意の新しい物体を再トレーニングなしで検出できます。
YOLOEの主な特徴:
オープンボキャブラリー検出:テキスト説明による任意の物体の検出が可能で、事前定義されたカテゴリに制限されません
プロンプトフリーモード:いかなる入力プロンプトもなく、画像内の顕著な物体を自動的に検出
効率的なデプロイ:YOLOの効率的なアーキテクチャを継承し、Raspberry Pi上でスムーズに動作
マルチタスクサポート:物体検出やインスタンスセグメンテーションを含む様々なタスクをサポート
これらの特徴により、YOLOEは迅速なプロトタイピングや、様々な物体を柔軟に検出する必要があるアプリケーションに特に適しています。
依存関係のインストール
まず、YOLOEに必要なCLIPライブラリをインストールします:
pip3 install git+https://github.com/ultralytics/CLIP.git --break-system-packages
プロンプトフリーモード
プロンプトフリーモードは、YOLOEを最も直感的に使用する方法です。このモードでは、テキスト入力なしで画像内のすべての顕著な物体を自動的に検出します。これは従来のYOLOと似た動作ですが、より優れたオープンボキャブラリー機能を持っています。
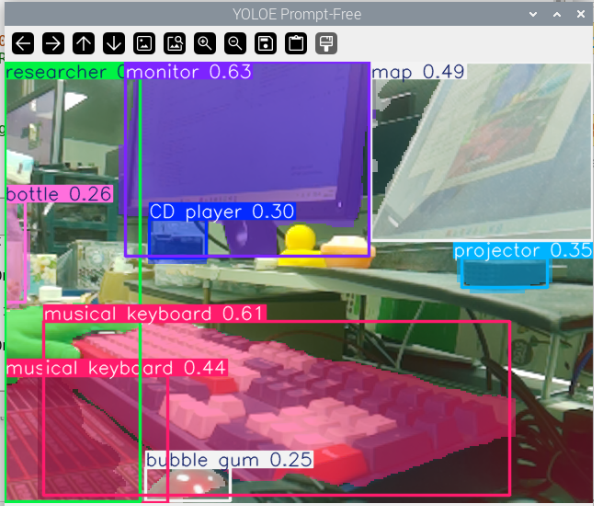
図:カメラを私の散らかった机に向けると、YOLOEのプロンプトフリーモードが視野内のすべての顕著な物体(モニター、キーボード、水の入ったカップ、ノート、マウスなど)を自動的に識別してセグメンテーションしました。各物体は異なる色のセグメンテーションマスクで注釈付けられており、テキスト入力は不要です。すべてが一目で明確に表示されます。
動作原理:モデルは視覚的特徴分析を通じて画像内の前景物体を自動的に識別し、セグメンテーションを実行します。このアプローチは画像内容の迅速な閲覧や、どの物体を検出する必要があるか不明な場合に適しています。
以下のコードは、Raspberry Pi上でYOLOEをプロンプトフリーモードで実行する方法を示しています:
cd ~/ai-lab-kit/yolo
python3 yoloe_prompt_free.py
from ultralytics import YOLO
from picamera2 import Picamera2
import cv2
# プロンプトフリーモード
model = YOLO("yoloe-11s-seg-pf.pt") # pf = prompt-free
picam2 = Picamera2()
picam2.preview_configuration.main.size = (640, 480)
picam2.preview_configuration.main.format = "RGB888"
picam2.configure("preview")
picam2.start()
print("プロンプトフリーモード: すべてを自動検出...")
print("「q」を押すと終了します")
while True:
frame = picam2.capture_array()
results = model.predict(frame, imgsz=320)
annotated = results[0].plot()
cv2.imshow("YOLOE プロンプトフリー", annotated)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
picam2.stop()
プロンプトフリーモードの特徴:
設定不要:画像内の顕著な物体を検出するために直接実行可能
自動セグメンテーション:検出フレームとセグメンテーションマスクの両方を出力
クラスラベルなし:カテゴリ名なしで検出された物体の位置のみ表示
ユースケース:クイックブラウジング、汎用物体検出、未知の物体の発見
テキストプロンプトモード
テキストプロンプトモードは、YOLOEの真の力を発揮する領域です。自然言語の説明を通じて、どの物体を検出するかをモデルに指示でき、モデルはそれらの物体をリアルタイムで識別し位置特定します。
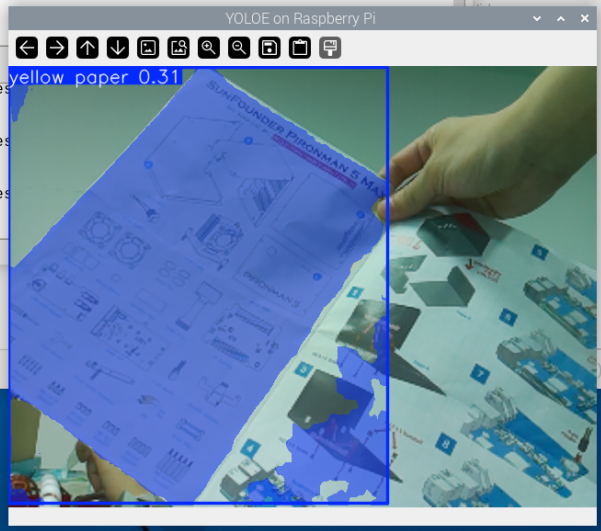
図:半分が黄色で半分が白い紙をカメラの前に持ち、「yellow paper」を探すようテキストプロンプトでモデルに指示しました。YOLOEはこの説明を正確に理解し、紙の黄色い半分だけをセグメンテーションしてバウンディングボックスでマークし、白い部分は完全に無視しました。これはYOLOEが自然言語を通じて粒度の細かい物体検出を実行する能力を示しています。
動作原理:モデルはテキストプロンプトを特徴ベクトルにエンコードし、画像特徴とマッチングしてテキスト説明に最も合致する領域を識別します。このアプローチにより、モデルを再トレーニングすることなく検出目標を動的に設定できます。
以下のコードは、テキストプロンプトを使用して特定の物体を検出する方法を示しています:
cd ~/ai-lab-kit/yolo
python3 yoloe_prompt_text.py
from ultralytics import YOLOE
from picamera2 import Picamera2
import cv2
# YOLOEモデルを読み込み
model = YOLOE("yoloe-26n-seg.pt") # ナノバージョン
# 検出するクラスを設定(テキストプロンプト)
names = ["yellow paper", "red cup", "person with glasses"]
model.set_classes(names, model.get_text_pe(names))
# カメラを初期化
picam2 = Picamera2()
picam2.preview_configuration.main.size = (640, 480)
picam2.preview_configuration.main.format = "RGB888"
picam2.configure("preview")
picam2.start()
print("YOLOEをテキストプロンプトで実行中、「q」を押すと終了...")
print(f"検出対象: {', '.join(names)}")
while True:
frame = picam2.capture_array()
results = model.predict(frame, conf=0.3) # 信頼度しきい値を0.3に設定
annotated = results[0].plot()
cv2.imshow("Raspberry PiでのYOLOE", annotated)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
picam2.stop()
テキストプロンプトモードの特徴:
動的検出:再トレーニングなしでいつでも検出目標を変更可能
自然言語:「青い車」「木製の椅子」などの日常的な言葉で物体を記述
マルチターゲット検出:同時に複数の検出目標を指定可能
粒度の細かい制御:色、材質、形状などの属性を記述可能
信頼度しきい値:
confパラメータで検出感度を制御
高度な応用
検出目標の動的切り替え
プログラムを再起動せずに、実行中にテキストプロンプトを変更できます:
# モデルを初期化
model = YOLOE("yoloe-26n-seg.pt")
# 初期の検出目標
current_names = ["red apple"]
model.set_classes(current_names, model.get_text_pe(current_names))
while True:
frame = picam2.capture_array()
# 検出目標を切り替えるか確認
key = cv2.waitKey(1) & 0xFF
if key == ord('1'):
current_names = ["banana"]
model.set_classes(current_names, model.get_text_pe(current_names))
print("検出対象: バナナ")
elif key == ord('2'):
current_names = ["orange"]
model.set_classes(current_names, model.get_text_pe(current_names))
print("検出対象: オレンジ")
results = model.predict(frame, conf=0.3)
annotated = results[0].plot()
cv2.imshow("YOLOE", annotated)
if key == ord('q'):
break
より複雑なテキスト説明の使用
YOLOEはより精密な物体位置特定のために複雑な自然言語説明をサポートしています:
# より精密な説明の例
names = [
"person with a red hat",
"car with open door",
"small dog on the left side",
"yellow paper on the desk"
]
model.set_classes(names, model.get_text_pe(names))
検出パラメータの調整
Raspberry Pi向けのパフォーマンス最適化:
# パフォーマンス最適化設定
results = model.predict(
frame,
imgsz=224, # より高速な処理のため低解像度に
conf=0.4, # より高い信頼度しきい値で誤検出を低減
iou=0.5, # IOUしきい値を調整
verbose=False # 詳細出力を無効化
)
パフォーマンス最適化のヒント
Raspberry Pi上でYOLOEを実行する際、以下の最適化がパフォーマンス向上に役立ちます:
適切なモデルの選択:
yoloe-26n-seg.pt:ナノバージョン、最速yoloe-11s-seg-pf.pt:Sバージョン、より高い精度だが低速
入力解像度の低減:
imgsz=224:最高速度imgsz=320:バランスの取れた選択(推奨)imgsz=416:より高い精度
信頼度しきい値の調整:
confパラメータを上げる(例:0.5)と検出数が減り、速度が向上
検出カテゴリの削減:
テキストプロンプトモードでは、
namesリストの長さを制限すると推論速度が向上
よくある質問
Q: YOLOEと従来のYOLOの違いは何ですか?
A: 従来のYOLOはトレーニング時に定義された固定カテゴリのみ検出できますが、YOLOEは再トレーニングなしでテキストプロンプトを通じて任意の物体を検出できます。
Q: プロンプトフリーモードはすべての物体を検出しますか?
A: プロンプトフリーモードは画像内の視覚的に顕著な物体を検出しますが、カテゴリラベルは提供されません。シーンの迅速な閲覧に適しています。
Q: テキストプロンプトは日本語をサポートしていますか?
A: モデルは主に英語データでトレーニングされているため、最良の結果を得るには英語のプロンプトをお勧めします。
Q: Raspberry Pi上でのYOLOEの速度はどのくらいですか?
A: Raspberry Pi 5では、ナノモデルと320解像度を使用して、3-5 FPSのリアルタイムパフォーマンスを達成できます。
Q: 複数のテキストプロンプトを同時に使用できますか?
A: はい、names リストに複数の説明を追加するだけで、モデルはそれらすべての物体を同時に検出します。