注釈
こんにちは、SunFounder Raspberry Pi & Arduino & ESP32 Enthusiast Community on Facebookへようこそ!他の愛好家と一緒に、Raspberry Pi、Arduino、ESP32の世界により深く入り込みましょう。
参加する理由
専門家サポート: 購入後の問題や技術的な課題を、コミュニティと私たちのチームの助けを借りて解決します。
学習と共有: ヒントやチュートリアルを交換して、スキルを向上させましょう。
限定プレビュー: 新製品の発表や先行プレビューに早期アクセスできます。
特別割引: 最新製品を特別割引でお楽しみいただけます。
季節限定キャンペーンとプレゼント: プレゼント企画やホリデーキャンペーンに参加しましょう。
👉 一緒に発見し、創造する準備はできましたか? [こちら] をクリックして、今すぐ参加しましょう!
3. カスタムYOLOモデルのトレーニング
独自のYOLOモデルをトレーニングするということは、基本的に、ディープラーニングアルゴリズムがあなたが提供した画像データから特定のオブジェクトを識別することを学習することを意味します。このプロセスは、子供に新しいものを認識するように教えることに似ています:さまざまな角度や環境からの多数の例画像を見せて、「これがターゲットオブジェクトです」と伝えます。十分な例を見た後、新しい画像でもそのオブジェクトを正確に識別できるようになります。
YOLOの場合、トレーニングプロセスは次のように機能します:
データ準備:ターゲットオブジェクトを含む画像を収集し、各オブジェクトの位置とカテゴリを注釈付けします
モデル学習:アルゴリズムは、これらの注釈付きデータを分析することで、オブジェクトの特徴を自動的に学習します
重みの作成:トレーニング完了後、学習した知識を含むモデルファイル(.ptファイル)が作成されます
推論アプリケーション:このモデルをRaspberry Piにデプロイし、新しい画像での検出に使用します
転移学習のおかげで、ゼロから始める必要はありません。Ultralyticsプラットフォームは、数百万の画像でトレーニングされた事前学習済みベースモデル(YOLOv8nなど)を提供しています。これらのモデルを少数の独自画像で「ファインチューニング」するだけで、効果的なカスタムモデルを作成できます。
写真の撮影
私たちのYOLOプロジェクトはRaspberry Piをベースにしているため、Raspberry Piカメラを使用して写真を撮影します。より良い結果を得るために、携帯電話を使って写真を撮り、データの多様性を高めることもあります。
写真撮影のヒント
鮮明さ:オブジェクトをできるだけ鮮明に撮影し、ぼやけを避けます
多様性:さまざまな角度(正面、側面、上面など)や異なる照明条件(明るい光、暗い光、逆光など)で写真を撮ります
背景のバリエーション:異なる背景で画像を撮影し、モデルが背景ではなくオブジェクトの本質的な特徴を学習するようにします
重なりを避ける:複数のオブジェクトを同時に撮影できますが、オブジェクト間の大きな重なりは避けます
数量の推奨:カテゴリあたり少なくとも50~100枚の写真を目指します。より多くの画像でより良い結果が得られます
どのオブジェクトを使用すべきか?
あなたが興味を持つ任意のオブジェクトを選んでトレーニングできます。例えば、ぬいぐるみ、カップ、椅子、あるいはペットなどです。このチュートリアルでは雪だるまのおもちゃを例として使用します。自分のターゲットオブジェクトに置き換えてください。
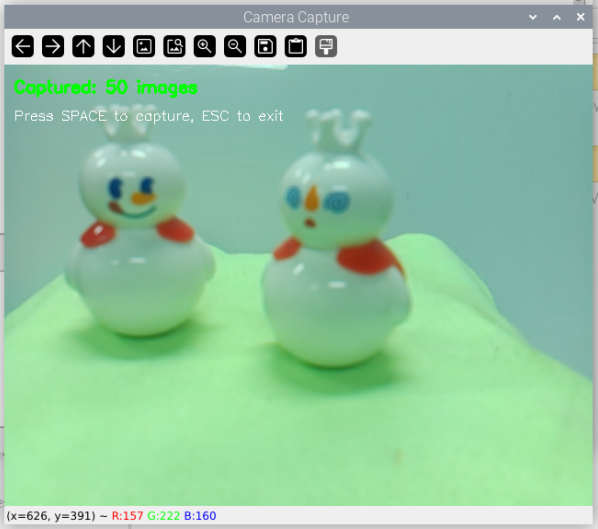
Raspberry Piカメラでの写真撮影
Raspberry Piカメラで写真を撮影するコードは以下の通りです:
cd ~/ai-lab-kit/yolo
python3 yolo_capture_images.py
#!/usr/bin/env python3
"""
Raspberry Pi用シンプルカメラキャプチャスクリプト
スペースキーでキャプチャ、ESCで終了
画像は ./captured_images/ に保存されます
"""
from picamera2 import Picamera2
import cv2
import os
import time
# 保存ディレクトリを作成
save_dir = "captured_images"
os.makedirs(save_dir, exist_ok=True)
# カメラを初期化
picam2 = Picamera2()
picam2.preview_configuration.main.size = (640, 480)
picam2.preview_configuration.main.format = "RGB888"
picam2.configure("preview")
picam2.start()
# カメラの準備ができるまで待機
time.sleep(1)
print("=== カメラキャプチャツール ===")
print(f"画像の保存先: {save_dir}")
print("操作方法:")
print(" スペースキー - 画像をキャプチャ")
print(" ESC - 終了")
print("==============================")
count = 0
try:
while True:
# フレームをキャプチャ
frame = picam2.capture_array()
# 指示付きで画像を表示
display = frame.copy()
cv2.putText(display, f"キャプチャ枚数: {count}", (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
cv2.putText(display, "スペースキーでキャプチャ、ESCで終了", (10, 60),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 1)
cv2.imshow("カメラキャプチャ", display)
# キー入力を待機
key = cv2.waitKey(1) & 0xFF
if key == 32: # スペースキー
# 画像を保存
filename = f"{save_dir}/img_{count:04d}.jpg"
cv2.imwrite(filename, frame)
print(f"キャプチャ: {filename}")
count += 1
# オプション: フラッシュ効果
flash = frame.copy()
flash[:] = (255, 255, 255)
cv2.imshow("カメラキャプチャ", flash)
cv2.waitKey(50)
elif key == 27: # ESCキー
print(f"\n終了します。総キャプチャ枚数: {count}")
break
finally:
cv2.destroyAllWindows()
picam2.stop()
print("カメラ停止")
画像をコンピューターに転送する
撮影後、FileZilla ソフトウェア を使用して画像をRaspberry Piからコンピューターにダウンロードします:
Raspberry PiのIPアドレスを確認:
hostname -IFileZillaでRaspberry Piに接続(ユーザー名:pi、パスワード:あなたのパスワード)
ディレクトリ
~/ai-lab-kit/yolo/captured_images/に移動すべての画像をコンピューターにダウンロード
モデルのトレーニング
オンラインの Ultralyticsプラットフォーム を使用します。このプラットフォームは、複雑なトレーニング環境を設定することなく、便利なモデルトレーニングサービスを提供します。
登録とログイン
右上の Get started をクリックして登録ページに進み、登録手続きを完了します。
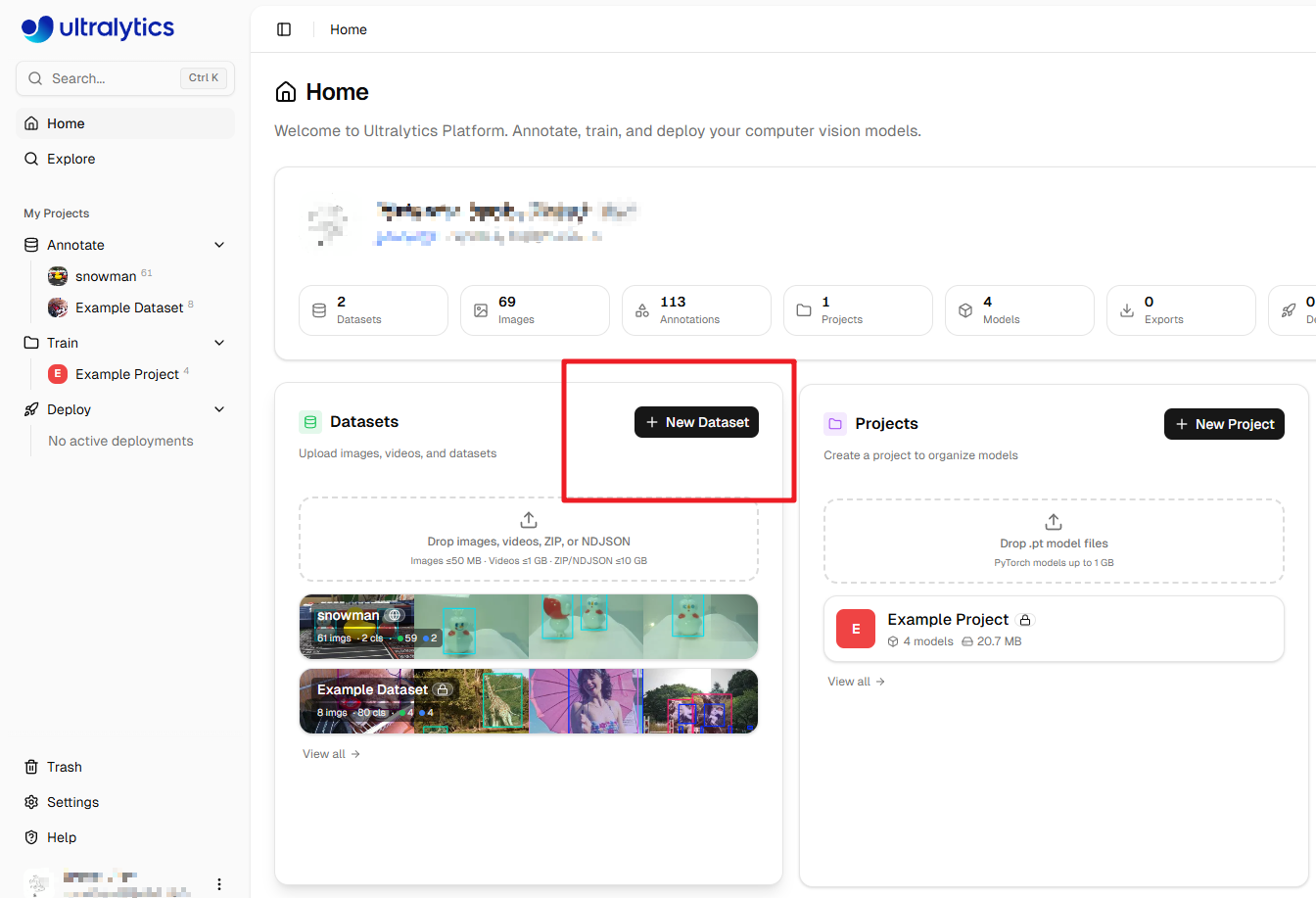
データセットの作成
登録後、ホームページにリダイレクトされます。New Dataset をクリックして新しいデータセットを作成します。
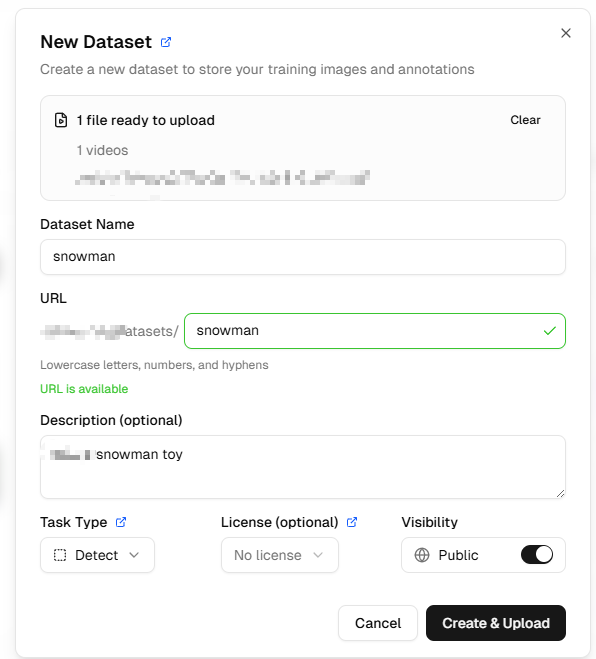
ウィンドウが開きます。ここでRaspberry Piで撮影した写真をアップロードし、データセット名 を入力します。その後 Create & upload をクリックします。
データセット画面に移動し、アップロードされたすべての画像を表示できます。
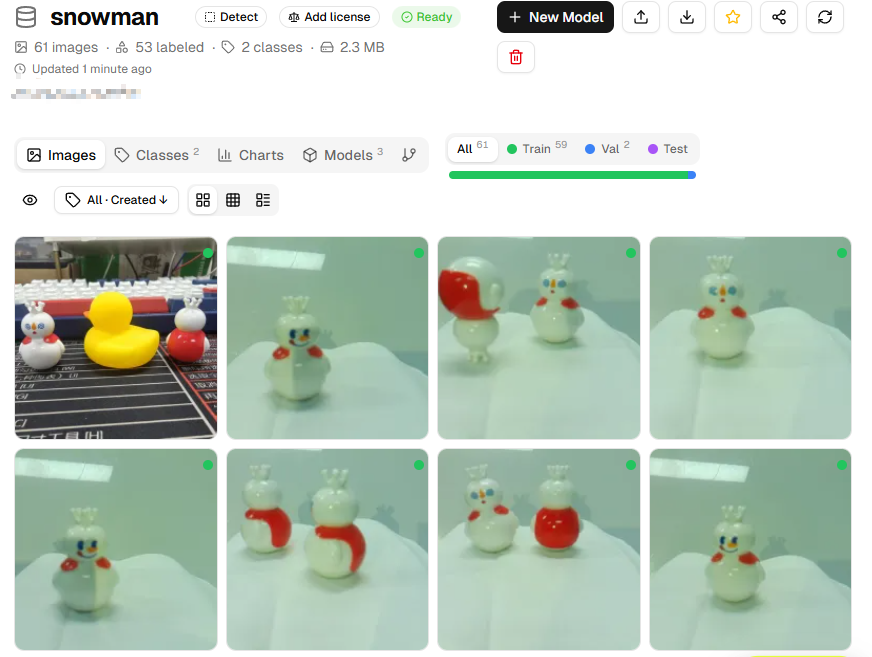
画像の注釈付け
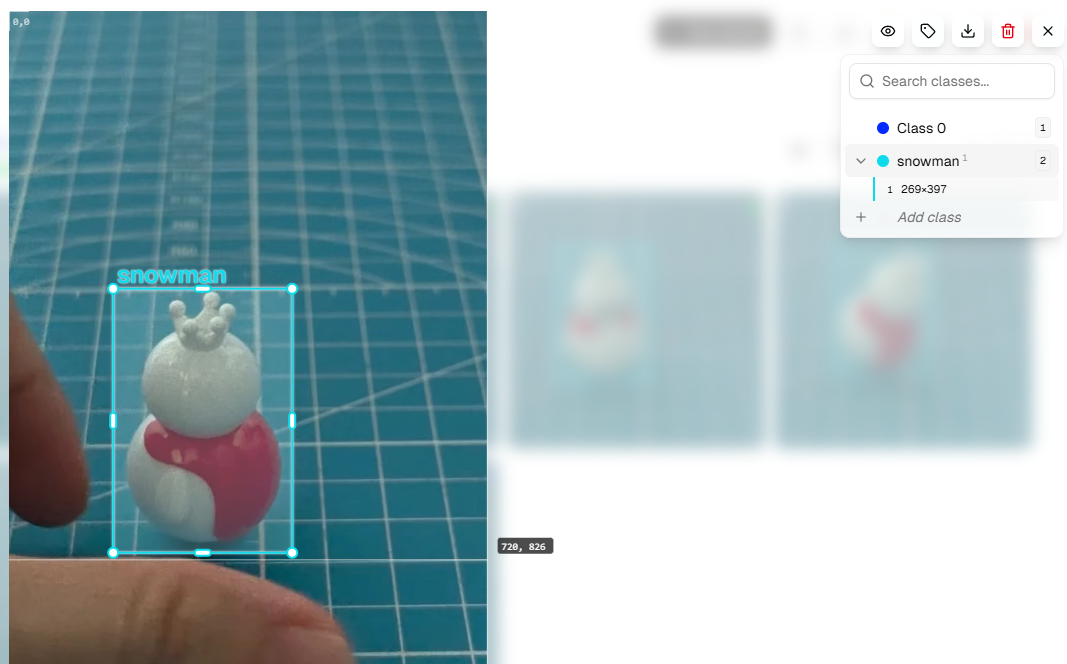
各写真を開いて注釈を付けます。右側の +Add Class ボタンを使用してカテゴリを追加します。識別したいオブジェクトに基づいて適切なカテゴリ名を追加します(例:カップを識別したい場合は「cup」、ペットを識別したい場合は「pet」を追加)。
注釈のヒント: - マウスでオブジェクトの周りにバウンディングボックスを描き、オブジェクトの端にできるだけ近づけます - 各オブジェクトが正確に注釈されていることを確認します - 画像にターゲットオブジェクトが含まれていない場合、注釈は不要です
すべての写真が注釈されるまで上記の手順を繰り返します。各画像の注釈が正確であることを確認します。
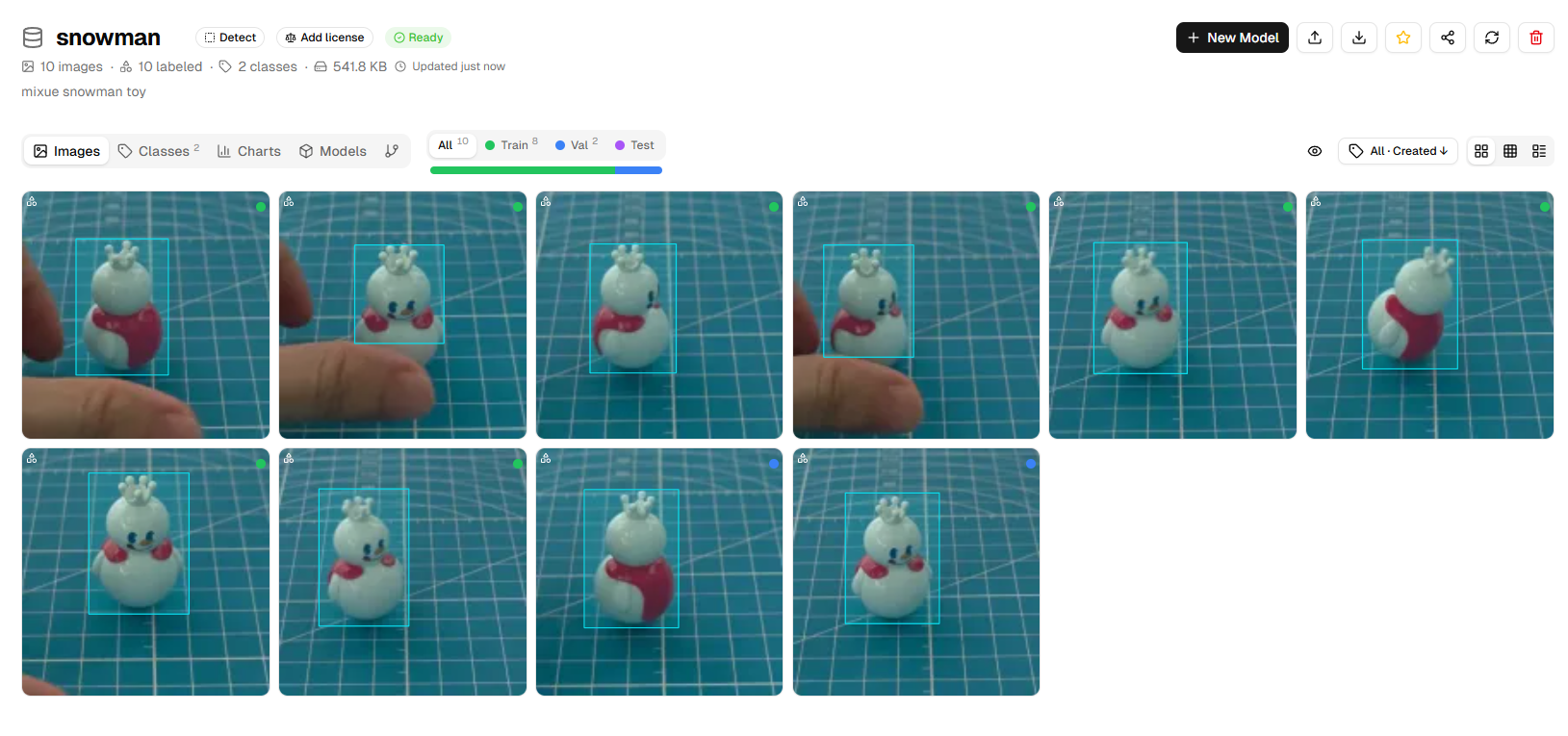
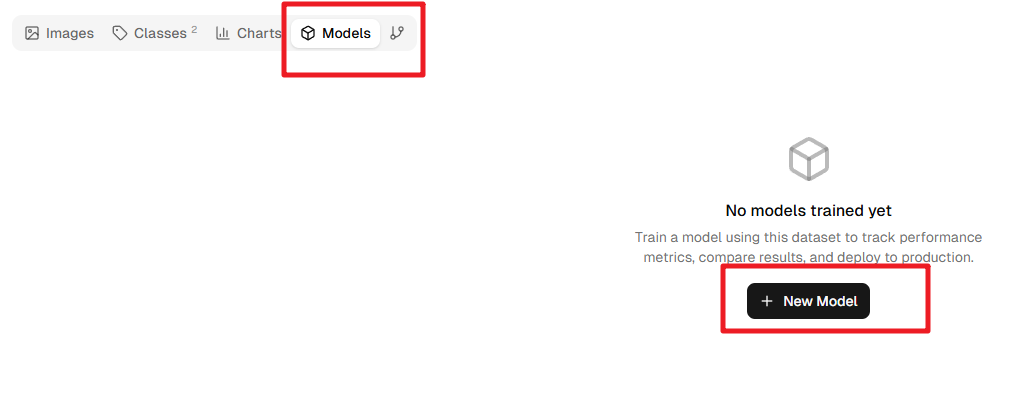
トレーニングモデルの作成
Models をクリックし、New Model をクリックします。
ポップアップウィンドウで、Base Model として YOLOv8n または YOLO11n を選択します。これらはRaspberry Piに適したナノバージョンで、小さく高速です。
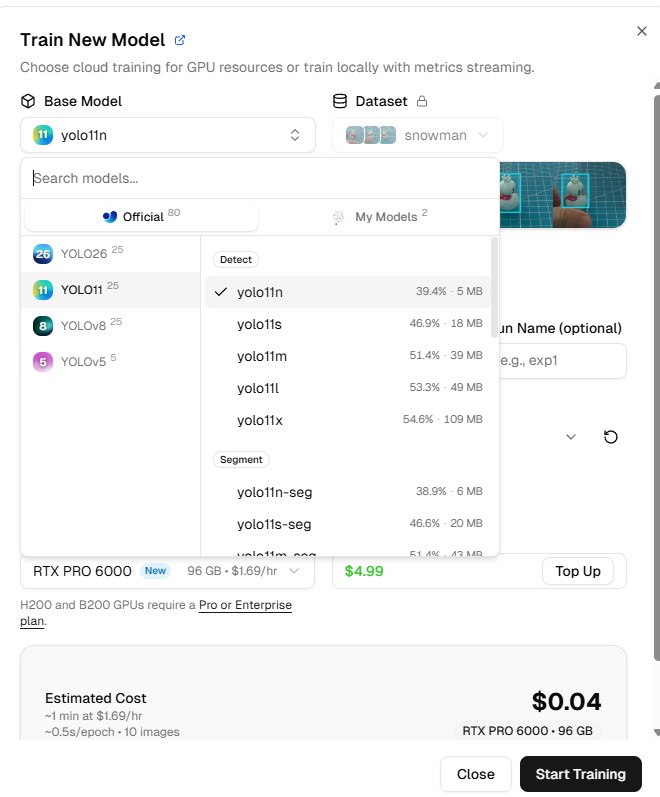
トレーニングパラメータを設定します:
Image size:320 を選択します(これはRaspberry Piが効率的に処理できる画像サイズです)
Epochs:デフォルト設定のままにします(通常50~100エポック)
GPU Type:特に指定はありませんが、GPUタイプによってトレーニング速度とコストが異なります
注意:新しいUltralyticsアカウントには5ドルのスタータークレジットが付与されます。小さなモデルのトレーニングには通常わずか数セントしかかかりません。必要に応じて使用してください。
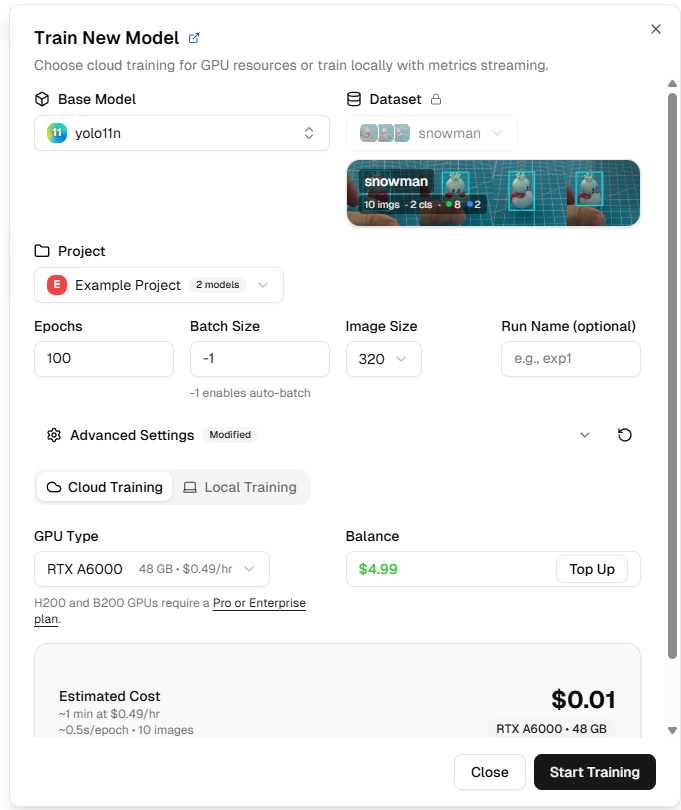
Start Training をクリックします。しばらく待つと(通常10~30分、データ量とGPUに依存)、モデルのトレーニングが完了します。
トレーニング中にリアルタイムメトリクスを確認できます:
box_loss:バウンディングボックスの損失。値が小さいほど良い
cls_loss:分類損失。値が小さいほど良い
mAP:平均適合率。値が高いほど良い(範囲0-1)
モデルのダウンロードとデプロイ
トレーニング完了後、Download PyTorch Model をクリックしてトレーニング済みモデルをダウンロードします(.ptファイルになります)。
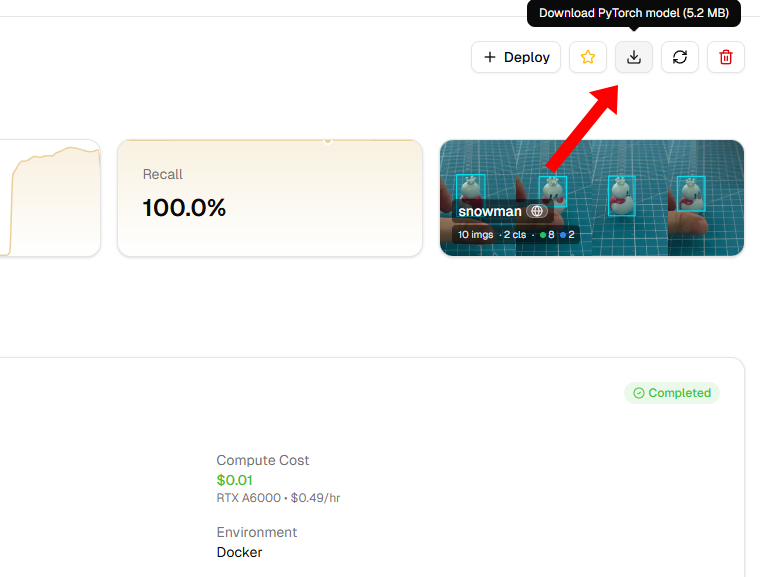
ダウンロード後、FileZillaを使用してRaspberry Piに転送します(推奨ディレクトリは
~/ai-lab-kit/yolo/)。
カスタムモデルの実行
モデルをRaspberry Piに転送したら、サンプルコード内のモデルパスを変更する必要があります。以下は完全な実行例です:
cd ~/ai-lab-kit/yolo
nano yolo_custom.py
モデル名を自分がダウンロードしたファイルに置き換えます:
#!/usr/bin/env python3
import cv2
from picamera2 import Picamera2
from ultralytics import YOLO
model = YOLO("your_model.pt") # あなたのモデル名に置き換えてください
# カメラを初期化
picam2 = Picamera2()
picam2.preview_configuration.main.size = (640, 480)
picam2.preview_configuration.main.format = "RGB888"
picam2.configure("preview")
picam2.start()
print("YOLOを開始しました。「q」を押すと終了します...")
try:
while True:
# フレームを取得
frame = picam2.capture_array()
# YOLOを実行し、imgsz=320を設定
results = model(frame, imgsz=320)
# 結果を描画
annotated = results[0].plot()
# 結果を表示
cv2.imshow("Raspberry PiでのYOLO", annotated)
# 「q」を押すと終了
if cv2.waitKey(1) & 0xFF == ord('q'):
break
finally:
cv2.destroyAllWindows()
picam2.stop()
print("終了しました")
結果の確認
サンプルコードを実行して、YOLOモデルがRaspberry Pi上でどのように機能するかを観察します:
python3 yolo_custom.pyすべてが正しく機能していれば、トレーニングしたターゲットオブジェクトがカメラ画像内でバウンディングボックスで囲まれ、カテゴリ名と信頼度が表示されているはずです。
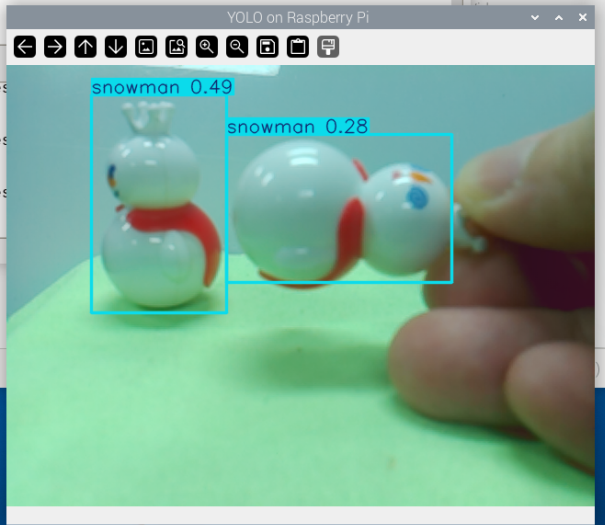
おめでとうございます!独自のYOLOモデルを正常にトレーニングし、Raspberry Piにデプロイしました。
トレーニングのヒントと推奨事項
モデルパフォーマンスの向上
データ量の増加:カテゴリあたり少なくとも50~100枚の画像を目指します
データ拡張:撮影時に角度、距離、照明を積極的に変化させます
ネガティブサンプル:ターゲットオブジェクトを含まない画像をいくつか追加して、誤検出を減らします
バランスの取れたデータセット:複数のカテゴリを識別する場合、各カテゴリで同様の画像数を確保します
よくある質問
モデルの検出結果が満足できない場合は?
注釈の精度を確認します
トレーニング画像の数を増やします
より大きなモデル(YOLOv8sなど)やより多くのトレーニングエポックを試します
さまざまなシナリオからの画像をさらに撮影します
トレーニングにはどのくらい時間がかかりますか?
約50枚の画像とYOLOv8nの場合、トレーニングには通常10~20分かかります
プラットフォームは選択されたGPUに基づいて自動的に調整されます
ローカルでトレーニングできますか?
はい、ただしPython環境とGPUドライバーを設定する必要があります。初心者には、アイデアを迅速に検証するためにUltralyticsプラットフォームをお勧めします。